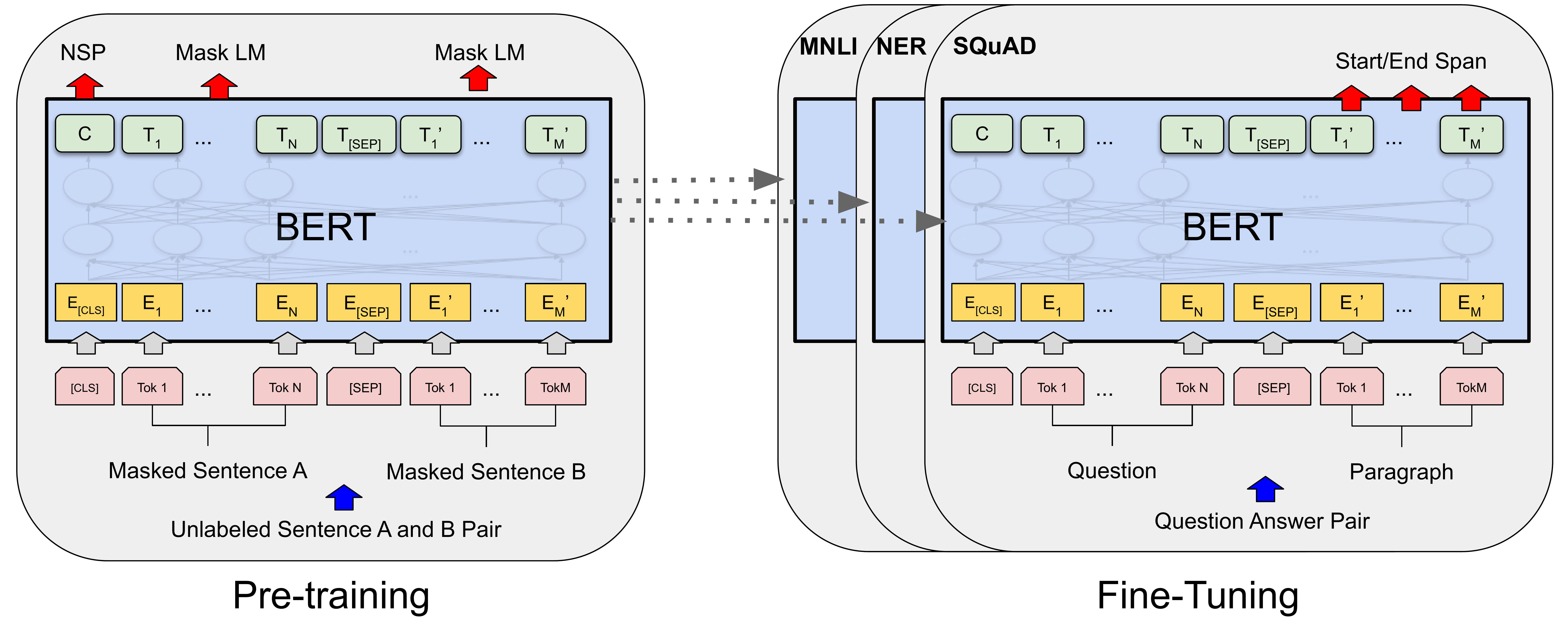
Frontier LLMs & Architectures
Transformers, mixture-of-experts, interpretability, retrieval, self-supervision, and training techniques for large models.
-
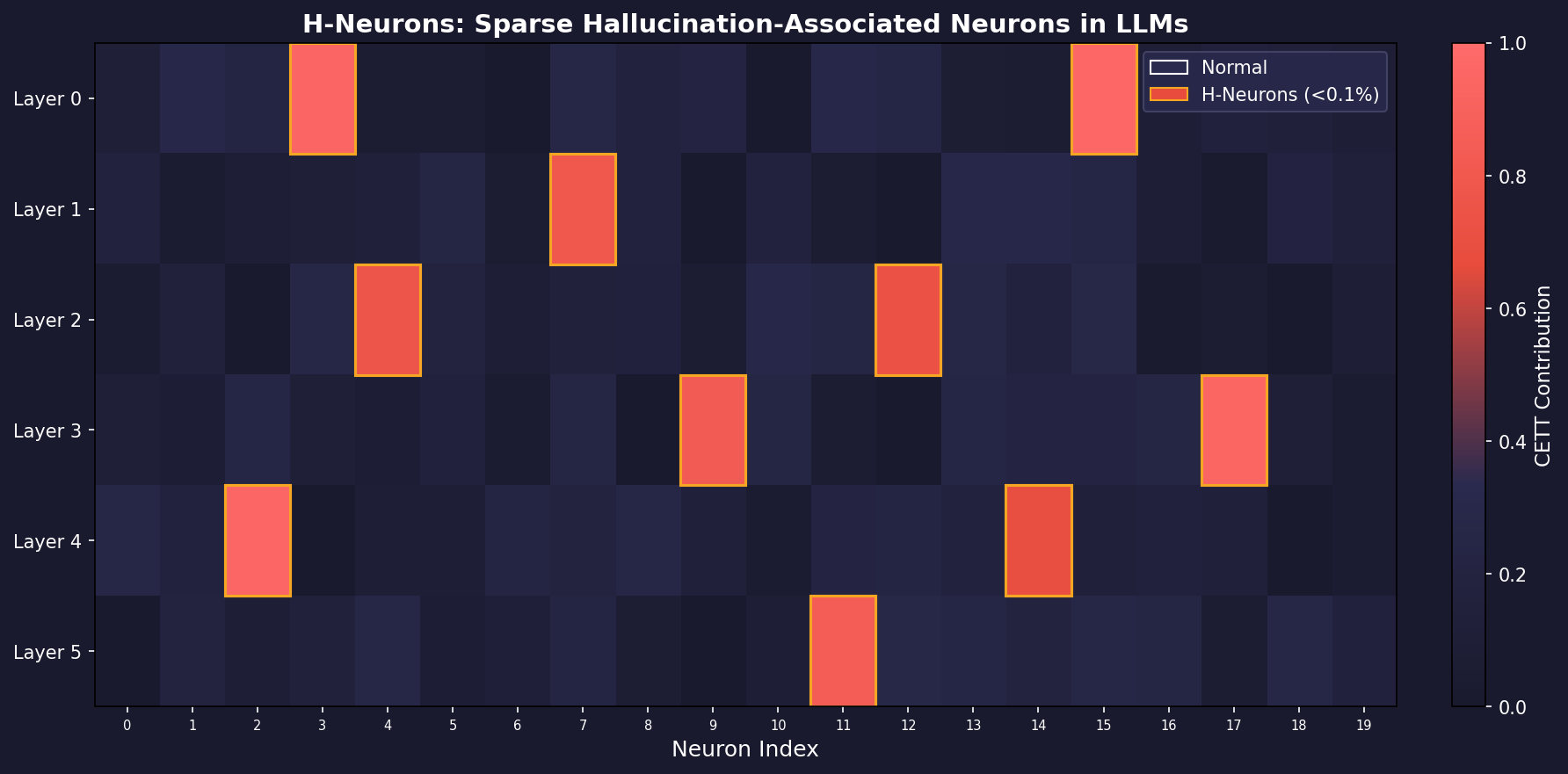
· H-Neurons: Hallucination at the Neuron Level
Gao et al. https://arxiv.org/abs/2512.01797 present a compelling investigation into the microscopic mechanisms of hallucination in LLMs. The central thesis is that hallucinations are not diffuse phenomena spread across millions of parameters, but are instead driven by a remarkably sparse subset of neurons -- fewer than 0.1% of the total -- which the authors term H-Neurons (Hallucination-associated Neurons).
-
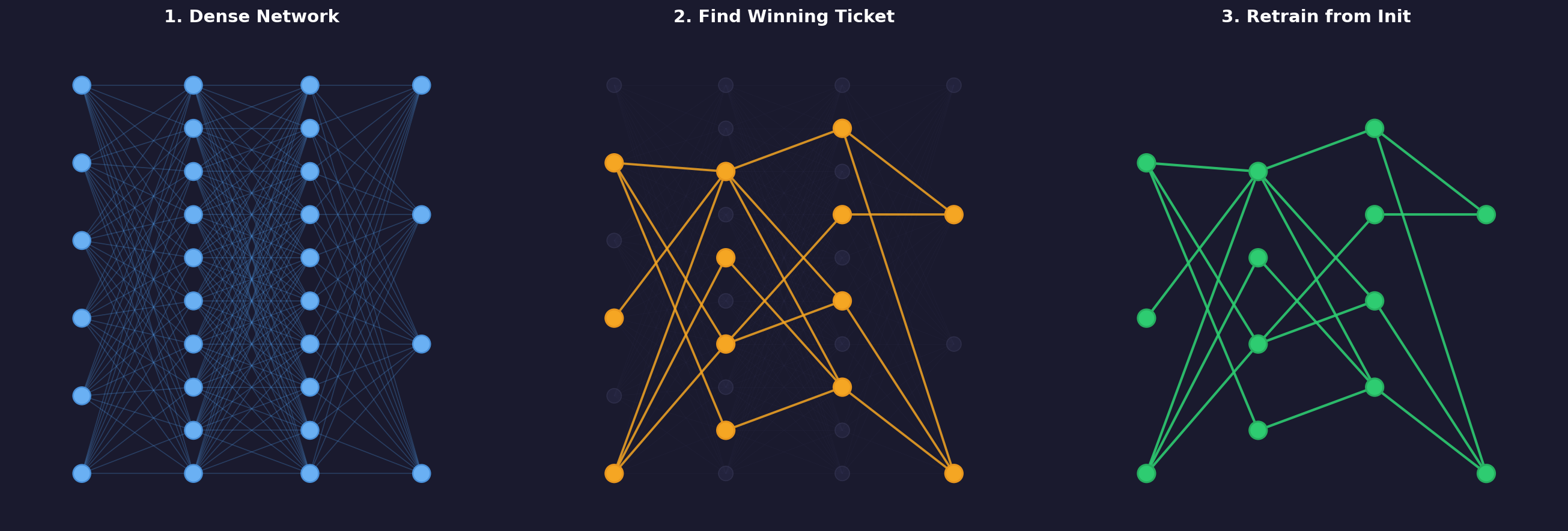
· The Lottery Ticket Hypothesis
In 2019, Frankle and Carlin published a paper https://arxiv.org/abs/1803.03635 that challenged a fundamental assumption in deep learning: that large, over-parameterized networks are necessary for achieving good performance. They proposed the Lottery Ticket Hypothesis, which states that dense, randomly initialized networks contain sparse subnetworks (winning tickets) that, when trained in isolation from the same initialization, can match the full network's accuracy.
-
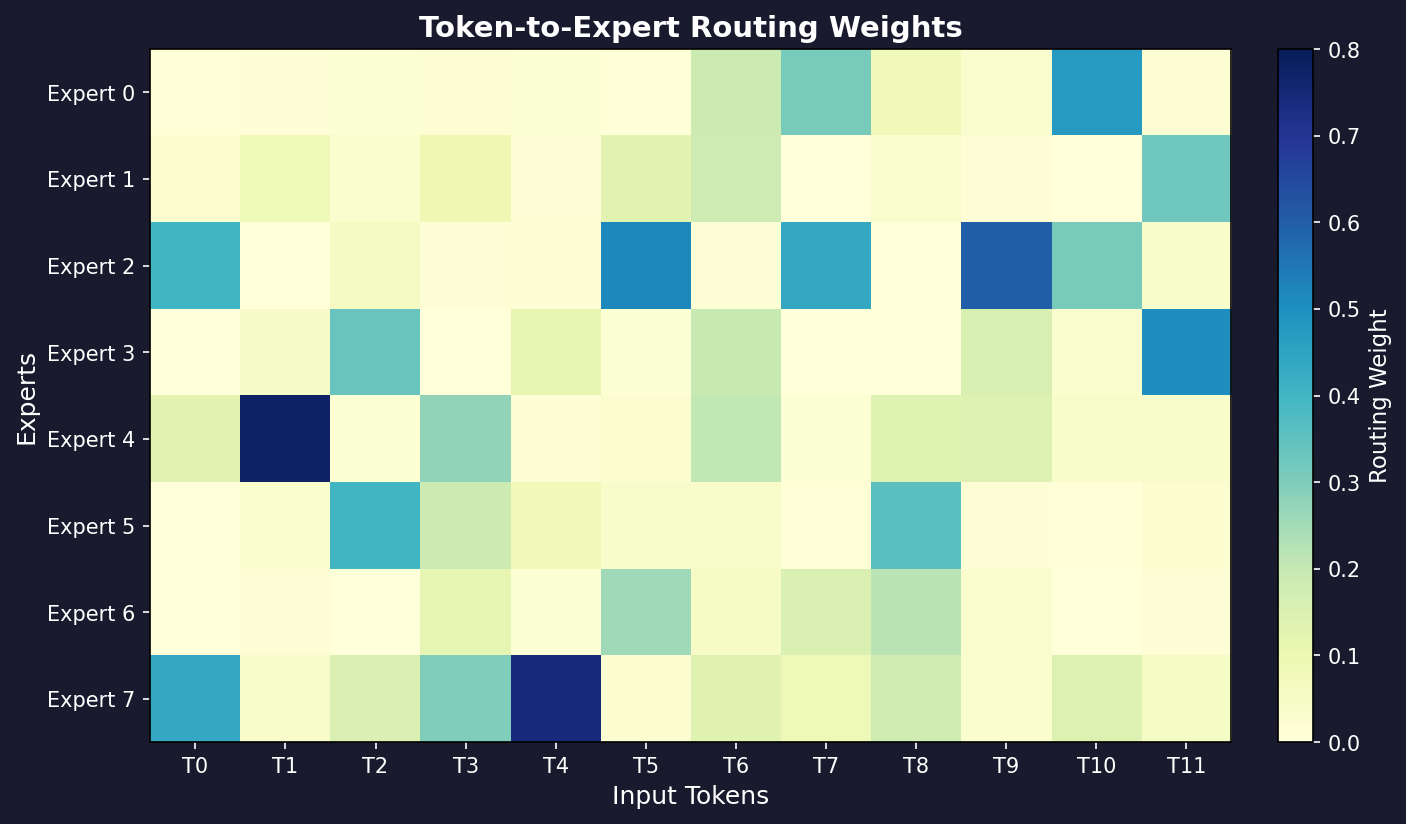
· Mixture of Experts
In the pursuit of scaling neural networks to unprecedented parameter counts while maintaining computational tractability, the paradigm of conditional computation has emerged as a cornerstone of modern deep learning architectures. A prominent and highly successful incarnation of this principle is the Mixture of Experts (MoE) layer. At its core, an MoE model eschews the monolithic, dense activation of traditional networks, wherein every parameter is engaged for every input. Instead, it employs a collection of specialized subnetworks, termed experts, and dynamically selects a sparse combination of these experts to process each input token. This approach allows for a dramatic increase in model capacity without a commensurate rise in computational cost (FLOPs), as only a fraction of the network's parameters are utilized for any given forward pass.
-
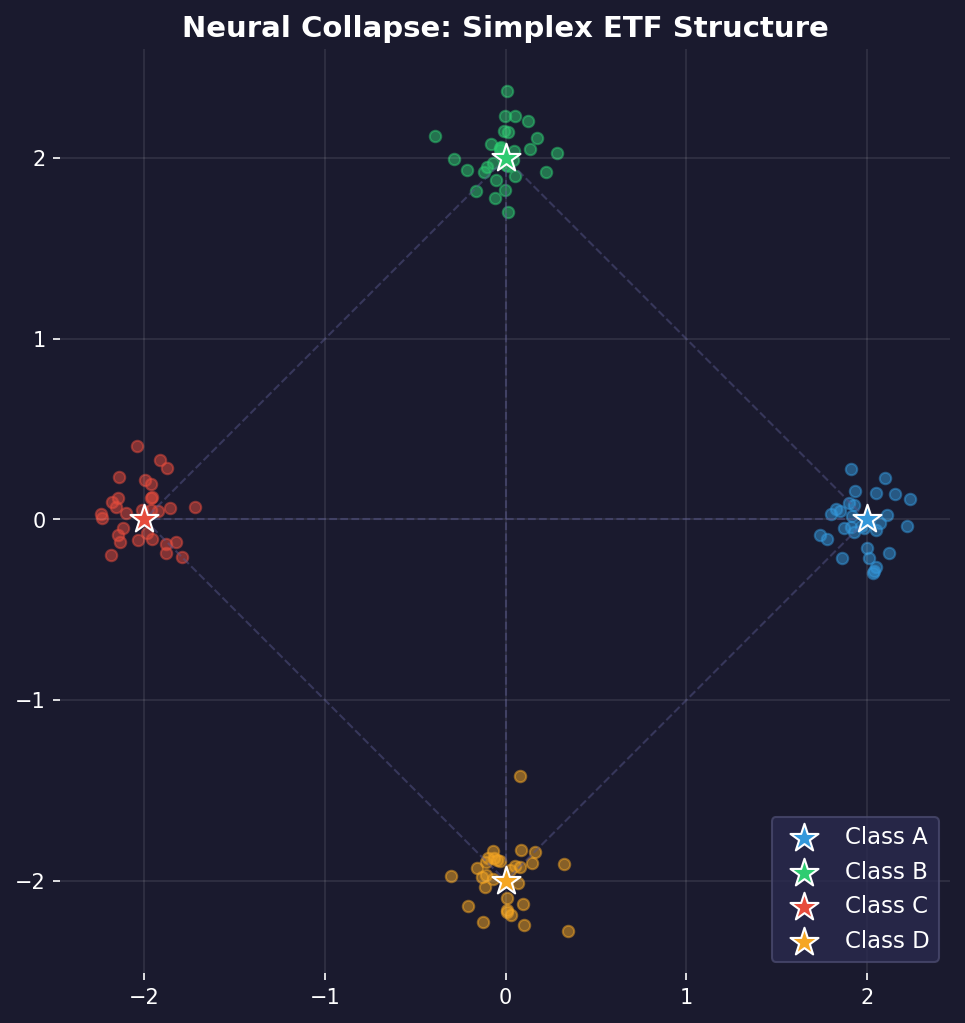
· What is Neural Collapse? A Simpler Look
Imagine you're training a very powerful neural network to recognize different classes of images, like cats, dogs, and cars. In the beginning, the network struggles, but eventually, it gets a perfect score on your training data.
-
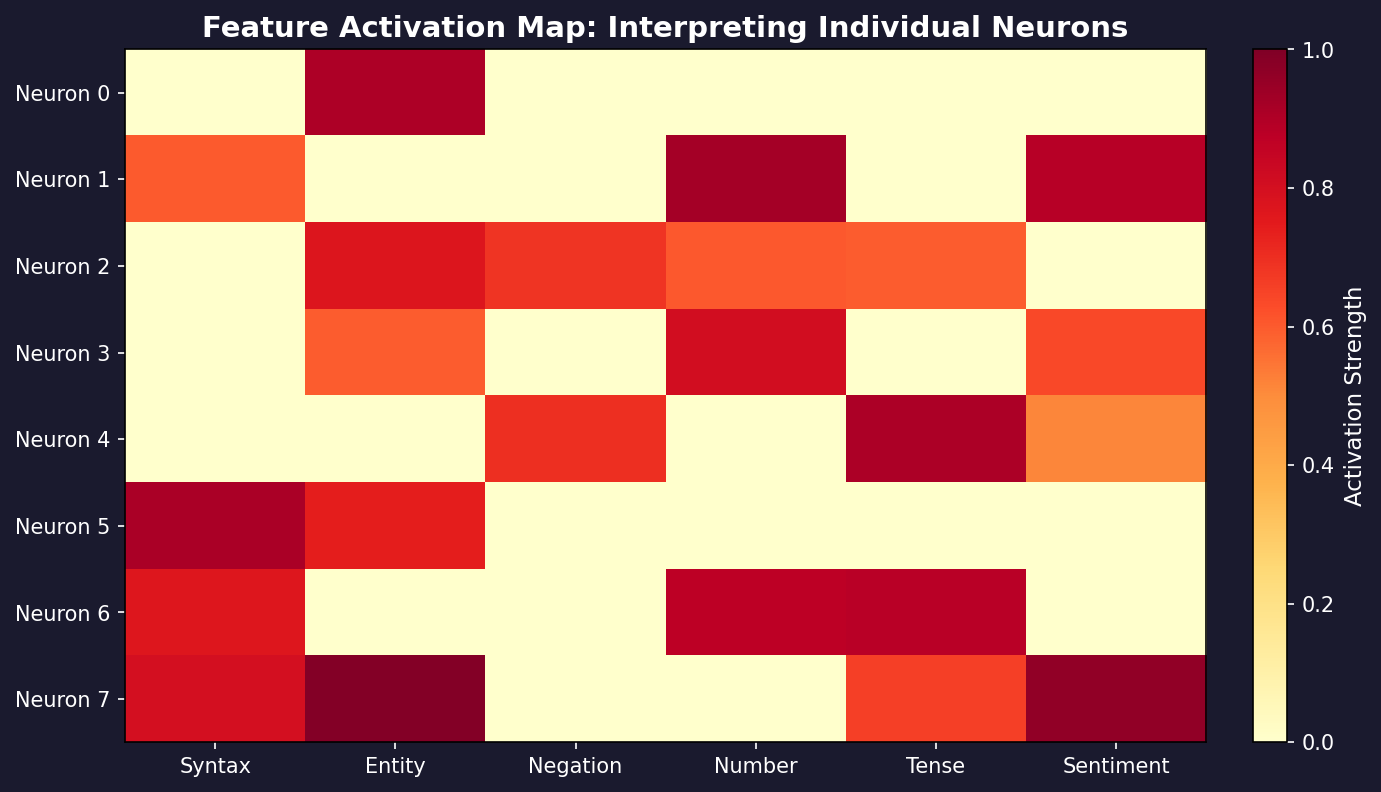
· Mechanistic Interpretability - Some concepts
Here are some quick notes on concepts in Mechanistic Interpretability. The subject is vast and very recent and try to interpret features for neural networks, specifically transformers and LLM's.
-
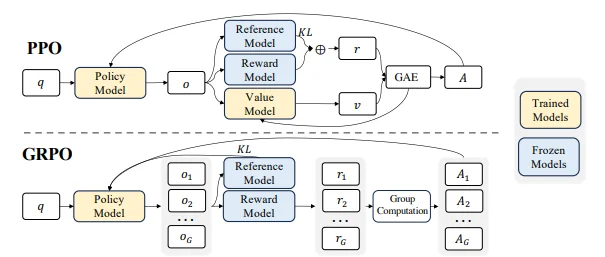
· Group Relative Policy Optimization (GRPO)
PPO is a reinforcement learning algorithm originally designed to update policies in a stable and reliable way. In the context of LLM fine-tuning, the model (the “policy”) is trained using feedback from a reward model that represents human preferences. Value Function (Critic): Estimates the “goodness” of a state, used with Generalized Advantage Estimation (GAE) to balance bias and variance. Basically it works as follows:
-
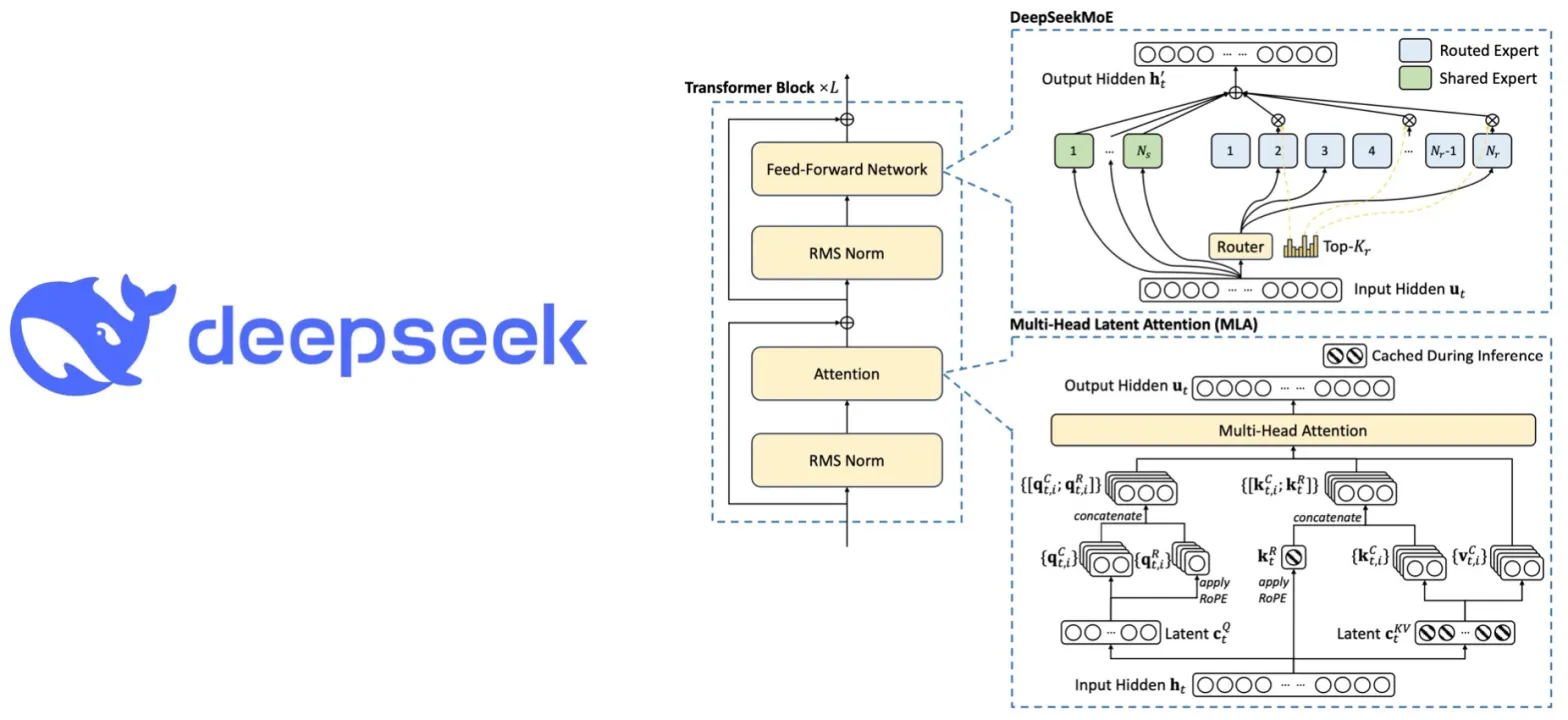
-
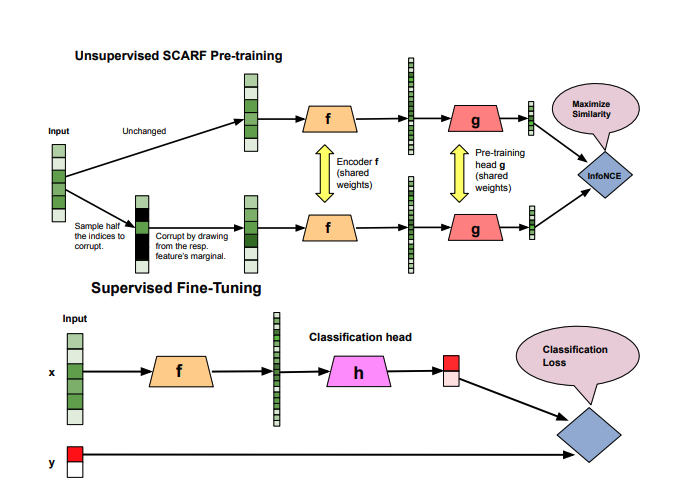
· Scarf: Self Supervised Learning for Tabular Data
Machine learning often struggles with the scarcity of labeled data. While unlabeled datasets are abundant, obtaining high-quality labeled data remains expensive and time-consuming. SCARF emerges as a breakthrough methodology that transforms how we extract meaningful representations from raw, untagged information.
-
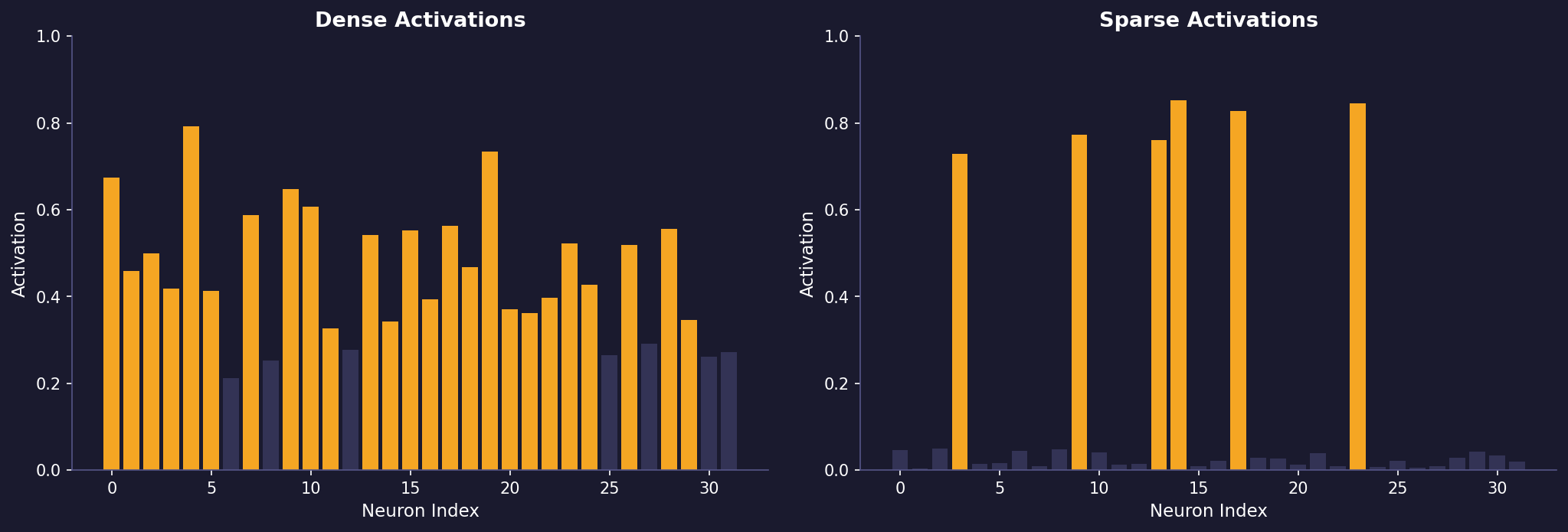
· Sparse Autoencoders
Sparse autoencoders are neural networks that learn compressed representations of data while enforcing sparsity - a constraint that ensures most neurons remain inactive for any given input. This approach leads to more robust and interpretable features, often capturing meaningful patterns in the data.
-
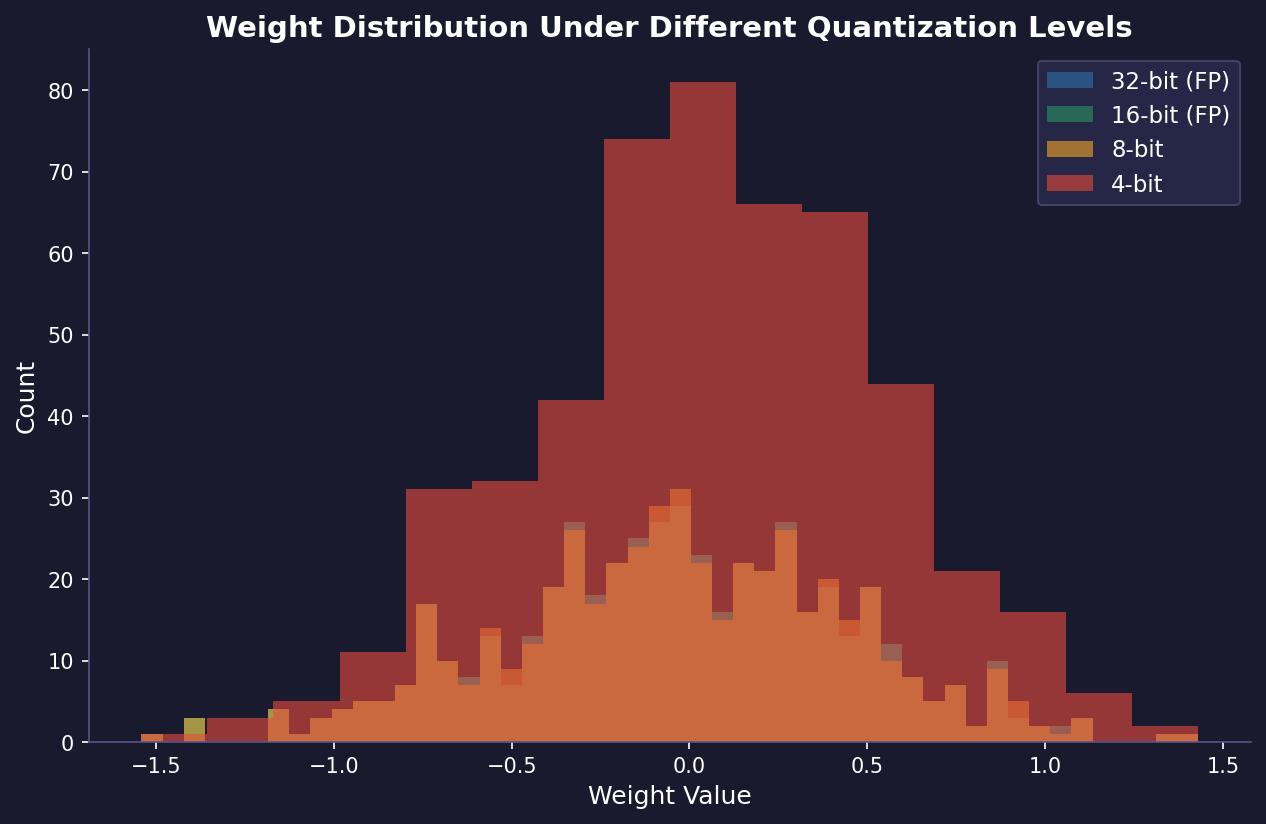
· Quantization of LLMs
The escalating complexity and scale of large language models (LLMs) have introduced substantial challenges concerning computational demands and resource allocation. These models, often comprising hundreds of billions of parameters, necessitate extensive memory and processing capabilities, making their deployment and real-time inference both costly and impractical for widespread use.
-
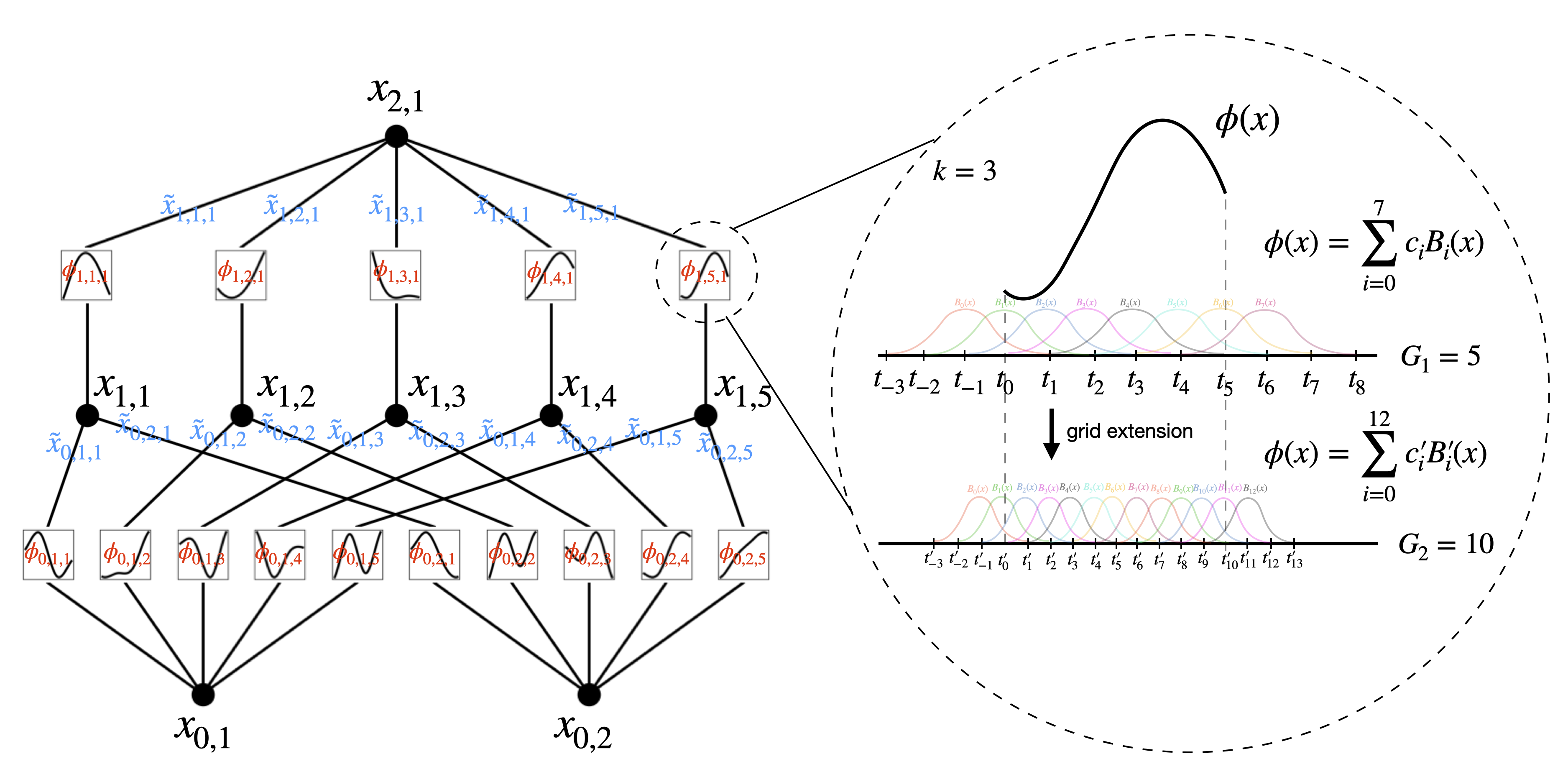
· Kolmogorov-Arnold Networks
I have been playing with some implementations of Kolmogorov-Arnold Networks. Here is an easy implementation for anyone who wants to try it out.
-
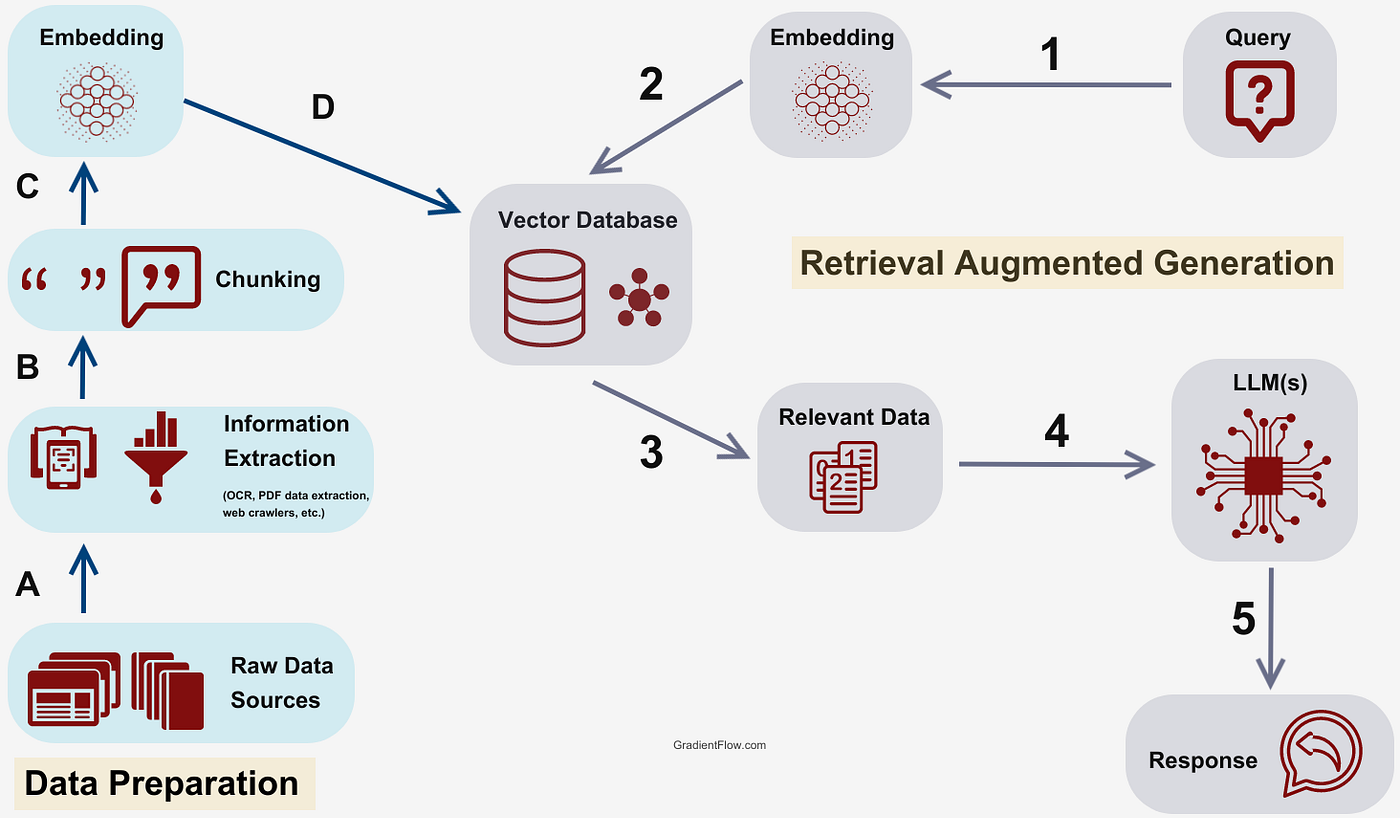
· Understanding and Implementing RAG (Retrieval-Augmented Generation)
Retrieval-Augmented Generation (RAG) is a powerful technique that combines the strengths of large language models with the ability to retrieve relevant information from external sources. This approach enhances the model's responses by grounding them in specific, up-to-date, or domain-specific knowledge.
-
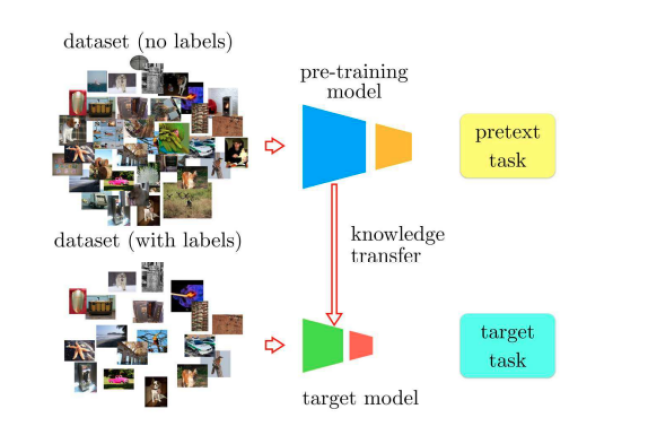
· Self Supervised Learning
This post is based on this blog post by meta Link to post.
-
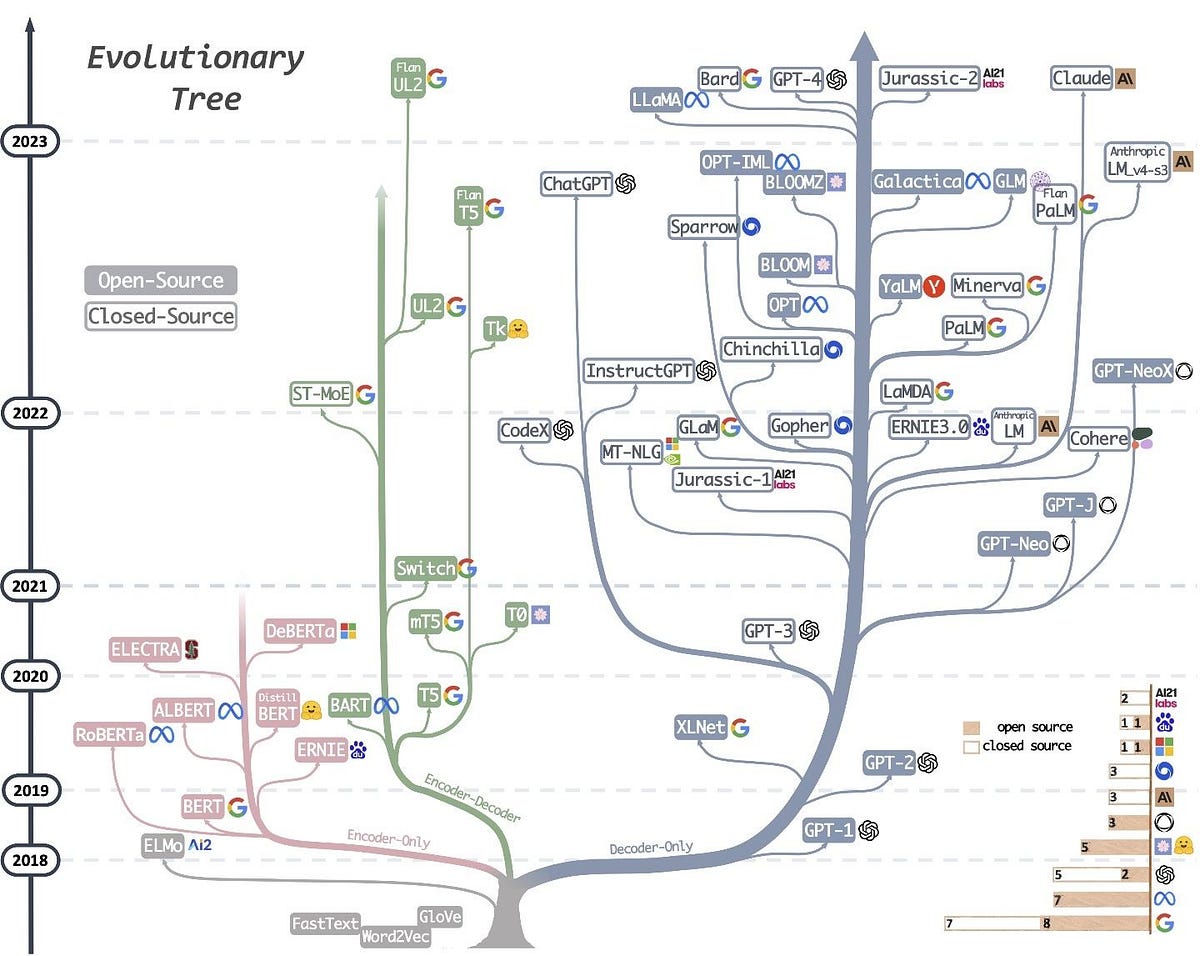
· Encoder vs Decoder vs EncoderDecoder Architectures
Language models are a crucial component in natural language processing (NLP). The architecture of these models can be broadly categorized into three types: encoder-only, decoder-only, and encoder-decoder architectures. Each of these architectures has distinct characteristics and applications.
-
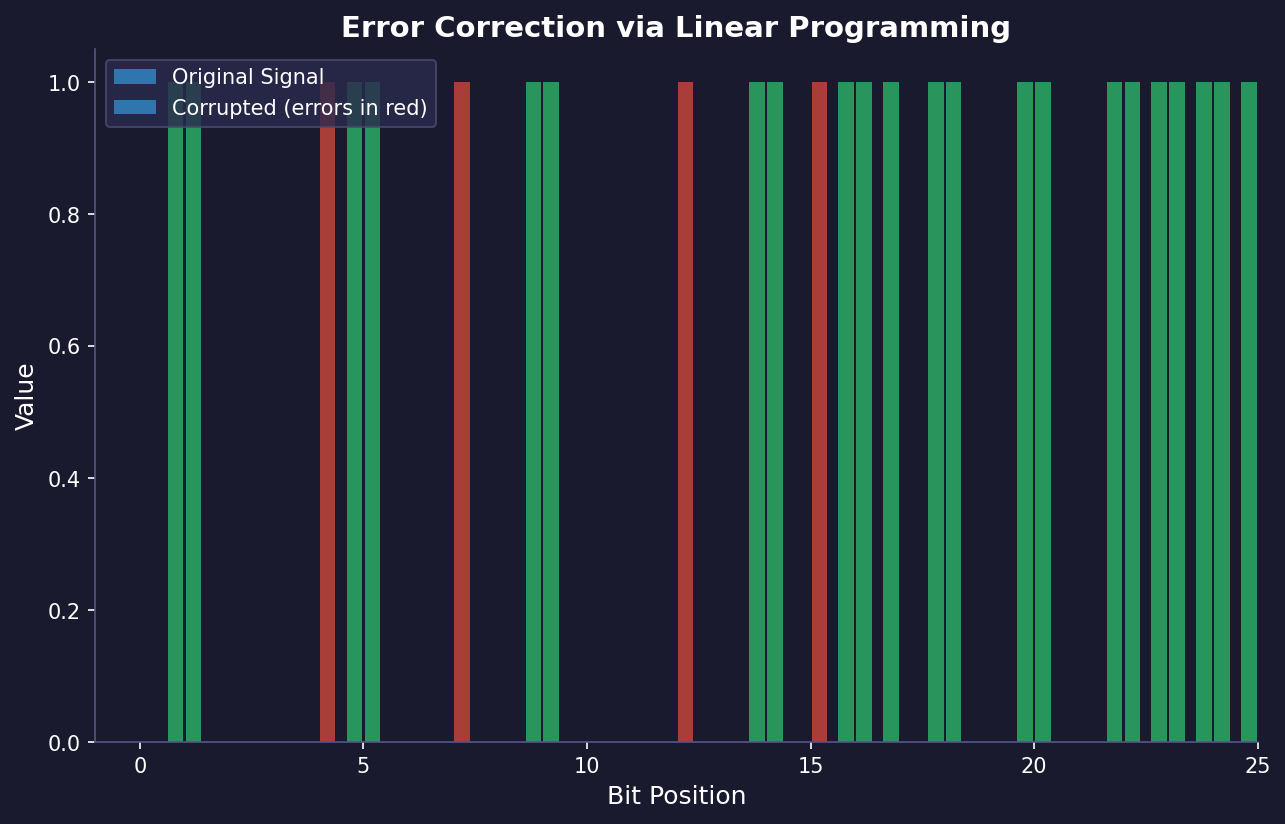
· Having fun with decoding and optimization
Hey. One topic very fascinating for me is coding theory. It can be very challenging and it can be pleasing for a more mathematical inclined person or someone like me that, likes a lot mathematics but like engineering as well. I think that the beginning of coding theory is strong related to Shannon work, A mathematical theory of communication but it can be interpreted in a very broad sense. What I mean by that is that a lot of natural phenomenum can be interpreted as an application of coding theory. For instance, you can consider the language as a coding theory application where what is done by expressing ourselfs in words is to find an optimal code for communicating thoughts. Other interesting example is what happens in natural evolution. Basically, there you can interpret the changes on environment and the DNA of species being on a communication channel where the DNA is coding the optimal way to survive on a given environment.
-
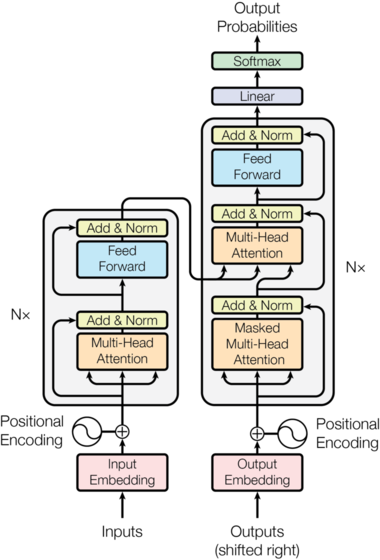
· Implementing the Transformer in Python
Hello everyone. Today the I will present a sketch of a transformer implementations. The focus here will be only on the forward pass of the architecture and not on learning the weights.
-