Self Supervised Learning
This post is based on this blog post by meta Link to post.
In recent years, AI has seen remarkable advancements, particularly in the development of AI systems that thrive on massive amounts of labeled data. This approach, known as supervised learning, has proven highly effective for training specialized models to perform specific tasks with incredible precision. However, while supervised learning has brought us this far, it has its limitations.
Particularly for creating generalist models—those capable of performing multiple tasks and acquiring new skills without needing large amounts of labeled data. The challenge is simple: it’s impossible to label everything in the world. Additionally, for certain tasks, there simply isn’t enough labeled data available. For example, training AI to understand low-resource languages faces significant challenges due to the scarcity of labeled examples.
To truly advance AI toward human-level intelligence, we need systems that can learn and adapt beyond the confines of their training data. This would involve AI systems developing a more nuanced understanding of the world, similar to how humans learn.
The Role of Common Sense in Intelligence
As humans, we learn about the world largely through observation and interaction. From an early age, we develop generalized predictive models about our environment, learning fundamental concepts like object permanence and gravity. This generalized knowledge, often referred to as common sense, is a cornerstone of human intelligence, enabling us to learn new skills with minimal instruction.
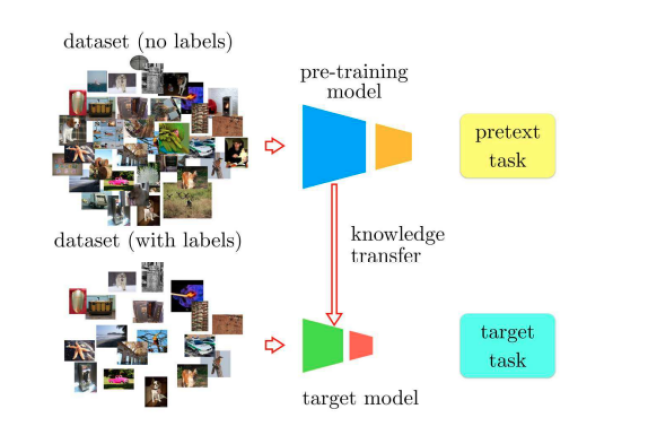
For AI to reach similar levels of understanding and adaptability, it needs to acquire a form of common sense—something that has remained a significant challenge in AI research. The question then becomes: how can we equip machines with this kind of background knowledge? The answers lies on SSL (Self Supervised Learning)
Enter Self-Supervised Learning
One of the most promising approaches to addressing this challenge is self-supervised learning (SSL). Unlike supervised learning, which relies on labeled data, self-supervised learning allows AI systems to learn from vast amounts of unlabeled data. This approach is crucial for recognizing and understanding more subtle, less common patterns in the world.
Self-supervised learning has already made significant strides in natural language processing (NLP). Models like Word2Vec, GloVe, BERT, RoBERTa, and others have been trained on large, unlabeled text datasets, resulting in systems that outperform those trained solely with supervised learning.
While SSL has seen considerable success in NLP, its application in computer vision (CV) has been more challenging. Representing uncertainty in image predictions is significantly more complex than in text. However, recent developments are starting to overcome these hurdles. A notable example is the SEER project, which leverages SSL to pretrain a large network on a billion random, unlabeled images. This approach has led to top accuracy on a diverse set of vision tasks, demonstrating that SSL can excel in complex, real-world CV settings as well.
Energy Based Models
One of the more exciting developments in SSL is the exploration of energy-based models (EBMs). EBMs measure the compatibility between inputs, making them particularly well-suited for tasks where prediction uncertainty is high, such as in CV. By training these models to recognize compatible and incompatible pairs of inputs, we can create systems that are better at making nuanced predictions.
Additionally, the use of joint embedding architectures, like Siamese networks, has shown promise in preventing the collapse of model training, where the system fails to differentiate between similar but distinct inputs. These architectures are being refined with both contrastive and non-contrastive methods to improve their effectiveness in SSL.
The future
Looking ahead, the challenge for AI researchers is to develop non-contrastive methods for latent-variable energy-based models that can produce robust representations of images, videos, and other signals. Achieving this will be a significant step toward creating AI systems that can learn and adapt with minimal labeled data, moving us closer to human-level intelligence.