Understanding and Implementing RAG (Retrieval-Augmented Generation)
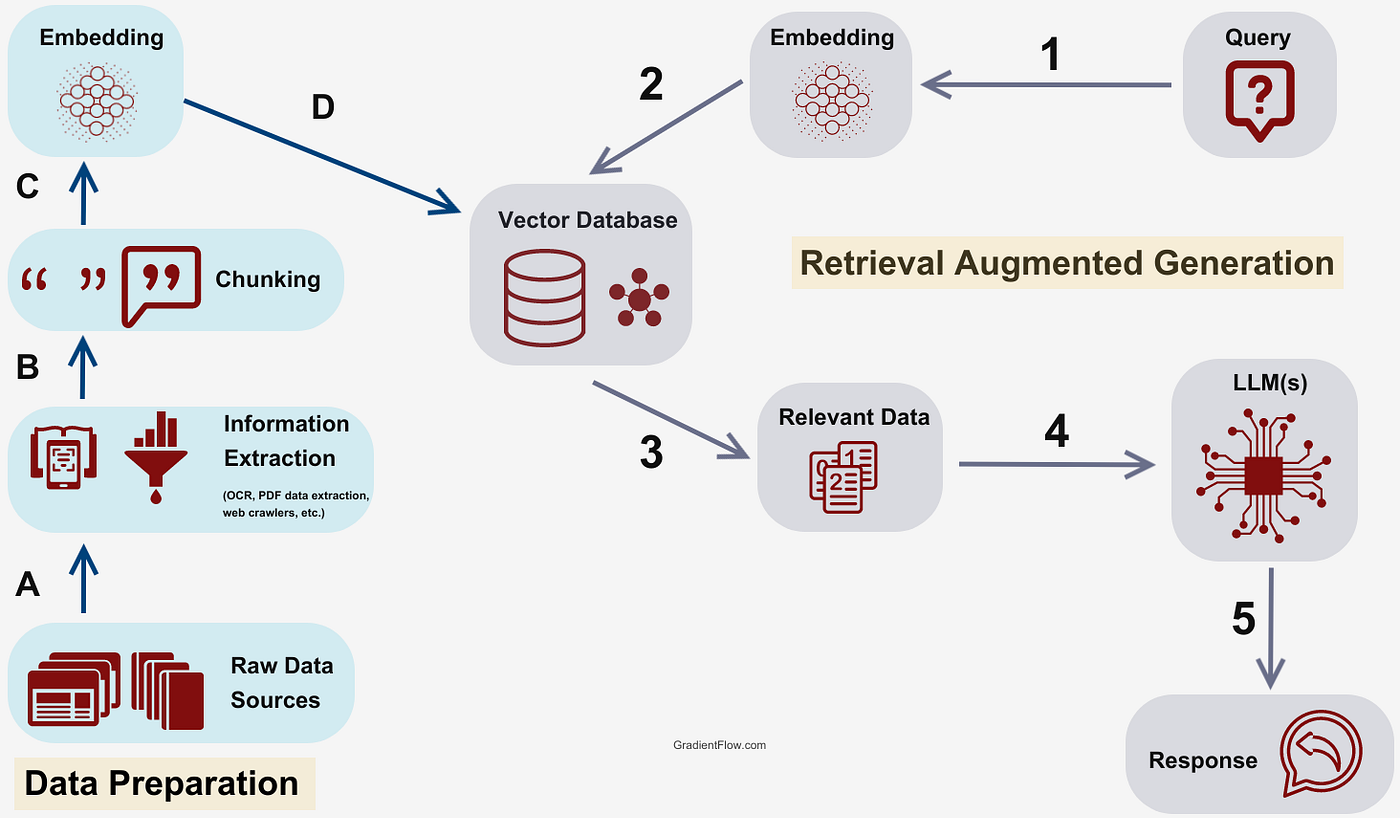
Retrieval-Augmented Generation (RAG) is a powerful technique that combines the strengths of large language models with the ability to retrieve relevant information from external sources. This approach enhances the model’s responses by grounding them in specific, up-to-date, or domain-specific knowledge.
RAG works by first retrieving relevant information from a knowledge base and then using that information to generate a response. This process involves three main steps:
- Retrieval: The system searches for relevant information in a database or document collection.
- Augmentation: The retrieved information is combined with the user’s query.
- Generation: A language model uses the augmented input to generate a response.
Implementing RAG with LangChain
Let’s look at a simple implementation of RAG using LangChain. This code is not ready for production use, but it is a good starting point for understanding RAG.
from langchain import OpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains import RetrievalQA
from langchain.document_loaders import TextLoader
# Load and prepare the document
loader = TextLoader("path_to_your_document.txt")
documents = loader.load()
# Split the document into chunks
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# Create embeddings and store them
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(texts, embeddings)
# Create a retriever
retriever = vectorstore.as_retriever()
# Initialize the language model
llm = OpenAI()
# Create the RAG chain
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)
# Use the RAG system
query = "What is the main topic of the document?"
response = qa_chain.run(query)
print(response)Here are the steps we took:
- We load a document and split it into smaller chunks.
- We create embeddings for these chunks and store them in a vector database (Chroma).
- We set up a retriever to fetch relevant information from the vector store.
- We initialize a language model (OpenAI’s GPT in this case).
- We create a RetrievalQA chain that combines the retriever and the language model.
- Finally, we can use this chain to answer questions based on the content of our document.