Scarf: Self Supervised Learning for Tabular Data
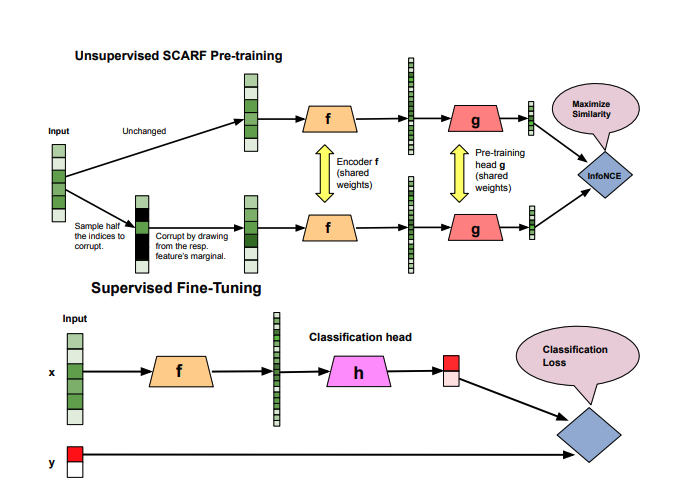
Machine learning often struggles with the scarcity of labeled data. While unlabeled datasets are abundant, obtaining high-quality labeled data remains expensive and time-consuming. SCARF emerges as a breakthrough methodology that transforms how we extract meaningful representations from raw, untagged information.
Innovation
SCARF introduces a novel approach to generating data views by strategically corrupting input features. Unlike domain-specific augmentation techniques, this method works universally across datasets:
- Randomly select a subset of features
- Replace selected features with samples from their empirical marginal distributions
- Leverage contrastive learning to maximize representation quality
Technical Mechanism
The approach employs:
- An encoder network (f)
- A pre-training head network (g)
- InfoNCE contrastive loss function
The core objective is generating representations that maintain semantic integrity while being robust to feature perturbations.
Tested across 72 real-world classification datasets, SCARF demonstrated significant improvements:
- Enhanced classification accuracy
- Improved performance under label noise
- Effective semi-supervised learning capabilities
- Domain-agnostic representation learning
- Minimal sensitivity to feature scaling
- Hyperparameter stability
- Compatibility with existing machine learning techniques
SCARF represents a pivotal advancement in self-supervised learning, offering a flexible, powerful approach to extracting meaningful representations with minimal labeled data.