What is Neural Collapse? A Simpler Look
Imagine you’re training a very powerful neural network to recognize different classes of images, like cats, dogs, and cars. In the beginning, the network struggles, but eventually, it gets a perfect score on your training data.
You might think that if you keep training it on the same data, it would either stop learning or get confused and “overthink” the problem. But something remarkable and unexpected happens instead: the network’s internal organization becomes incredibly simple and tidy. This process of self-organization into a perfect, simple structure is called Neural Collapse.
It’s driven by the network’s hidden preference to find the most efficient and straightforward solution possible, even after it has already solved the main problem. Neural Collapse can be broken down into four distinct things that happen at the same time during the final stages of training.
- All Examples of a Class Become One (Variability Collapse)
The network learns to ignore the unique details of individual images within the same class.
Example: Instead of creating slightly different internal “codes” for a fluffy Persian cat, a sleek Siamese cat, and a tabby cat, the network starts producing the exact same internal code for all of them. It effectively creates a single, perfect, “ultimate cat” representation and throws away all the variation.
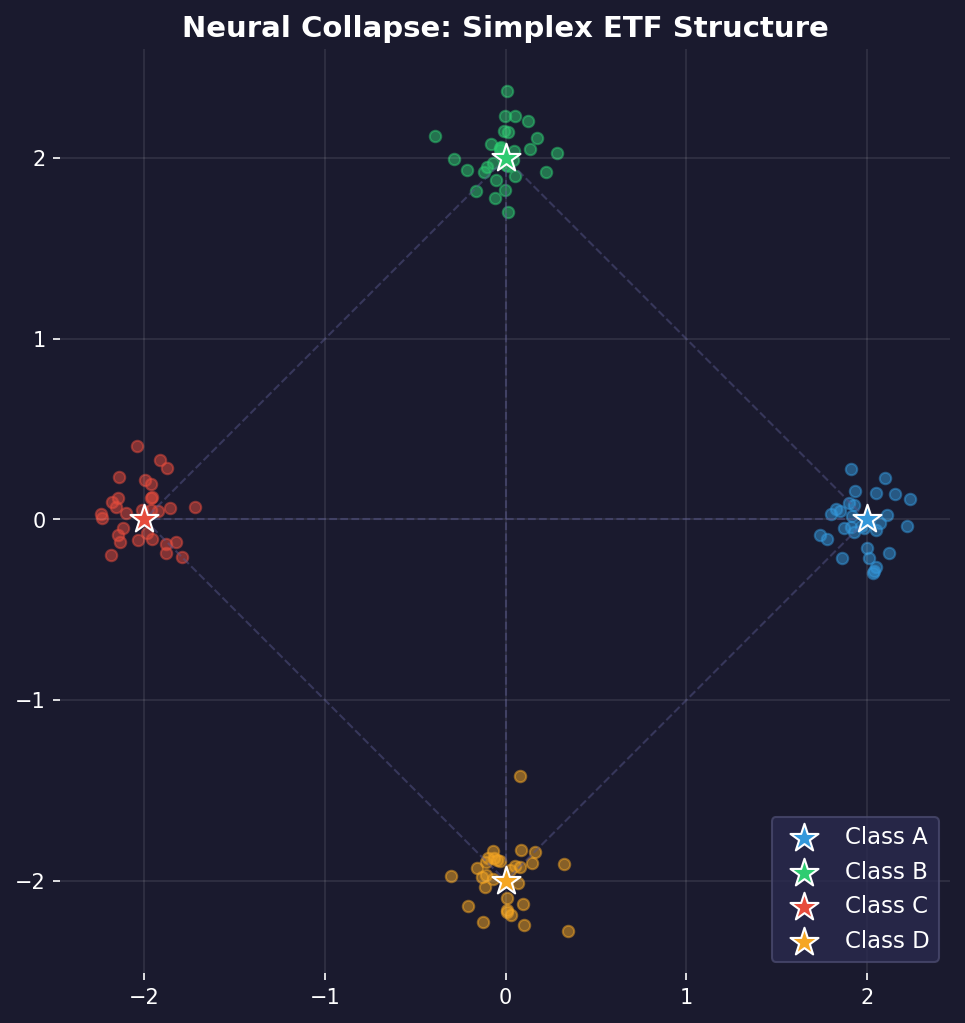
- Class Codes Spread Out Perfectly (The Symmetrical Shape)
Once the network has a single “code” for each class (like “ultimate cat,” “ultimate dog,” and “ultimate car”), it arranges these codes in the most spread-out way possible.
Example: If you have three classes, their codes will form the points of a perfect equilateral triangle in the network’s internal space. If you have four classes, they form a tetrahedron. This is the most symmetrical and separated arrangement possible, making the classes maximally distinct from one another. This perfect geometric structure is called a Simplex ETF.
- The Decision-Maker Aligns Perfectly (Self-Duality)
The final part of the network that makes the decision (the “classifier”) also simplifies. The classifier’s internal template for “cat” perfectly lines up with the network’s “ultimate cat” code. The decision-maker becomes a perfect mirror of the data’s new, simple structure.
- The Whole System Becomes a Simple “Nearest-Neighbor” Game
Because of the three changes above, the network’s complex decision-making process becomes incredibly simple. To classify a new image:
Example: The network creates a code for the new image. Then, it just checks which of its “ultimate” class codes (the points of the triangle or tetrahedron) is the closest. If the “ultimate cat” code is the nearest neighbor, it classifies the image as a cat. The sophisticated deep network ends up behaving like a much simpler classifier.
To help people see this, researchers created animations showing the process. Imagine little blue balls (individual images) clustering together into a single point for each class. These points (class means) then move to form a perfect symmetrical shape (the green target points), and the decision-maker (red lines) aligns with them perfectly. This drive towards simplicity has important consequences.
-
The Good: The super-organized structure makes the network very good at its main job and very good at identifying things that are completely different from what it was trained on. The neat, tight clusters make it easy to spot an outsider.
-
The Trade-Off (The Bad): This simplicity comes at a cost. By erasing all the subtle details within a class, the network can hurt its ability to learn new, related things later.