Encoder vs Decoder vs EncoderDecoder Architectures
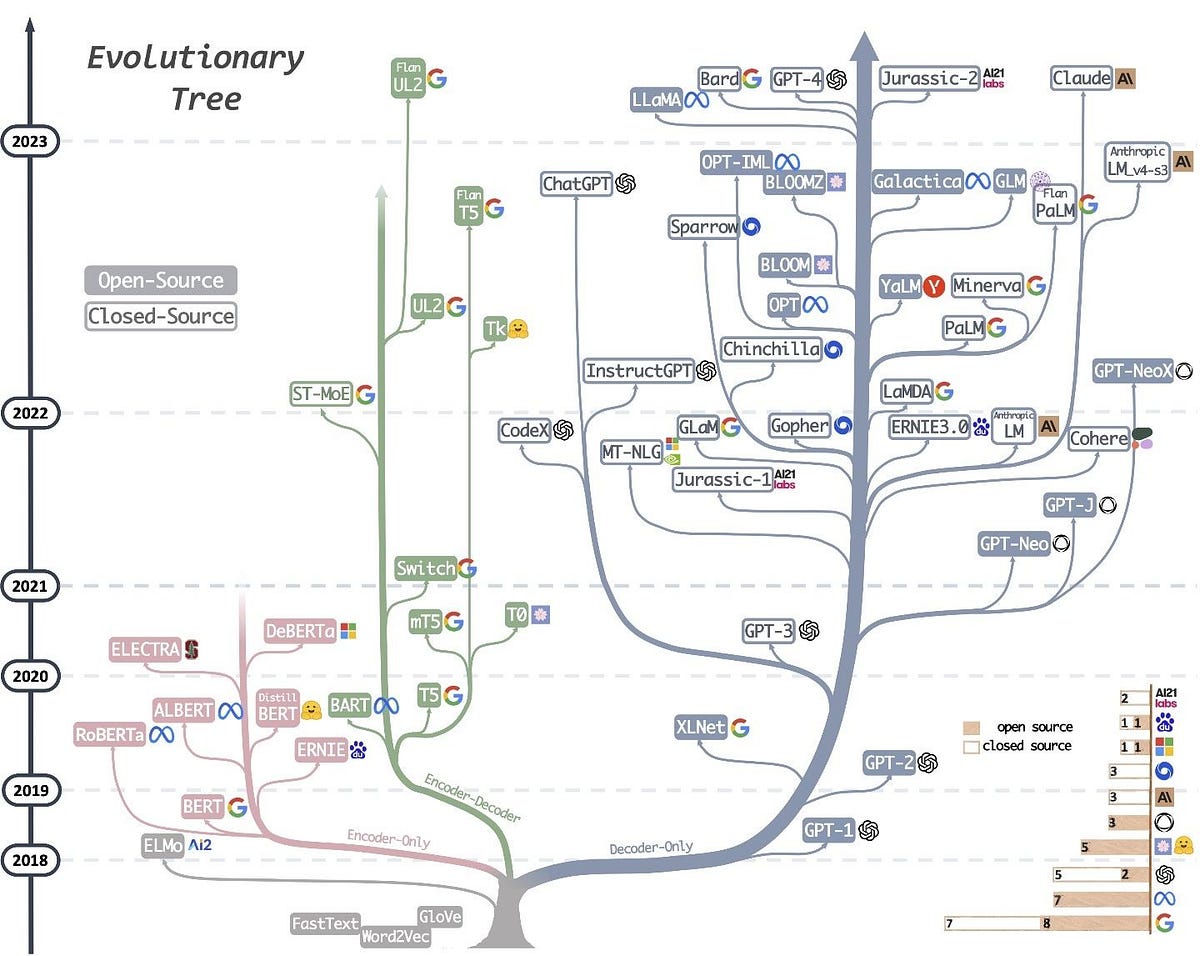
Differences Between Encoder-Only, Decoder-Only, and Encoder-Decoder Architectures for Language Models
Language models are a crucial component in natural language processing (NLP). The architecture of these models can be broadly categorized into three types: encoder-only, decoder-only, and encoder-decoder architectures. Each of these architectures has distinct characteristics and applications.
1. Encoder-Only Architectures
Encoder-only architectures are designed to transform an input sequence into a fixed-size context representation. These architectures are primarily used for tasks that require understanding the input context, such as text classification, named entity recognition, and sentiment analysis. Some examples are BERT and RoBERTa.
- Self-Attention Mechanism: Captures dependencies between tokens in the input sequence.
- Bidirectional Context: Can capture context from both past and future tokens simultaneously.
- Tasks: Best suited for tasks where the entire input sequence is available at once.
Architecture
- Input Layer: The input sequence is tokenized and embedded into continuous vector representations.
- Encoder Layer: Consists of multiple layers of self-attention and feed-forward neural networks. The self-attention mechanism allows the model to weigh the importance of different tokens in the sequence relative to each other.
- Output Layer: The final hidden states from the encoder layers are used for downstream tasks.
2. Decoder-Only Architectures
Decoder-only architectures generate sequences by predicting the next token given the previous tokens. These architectures are primarily used for tasks that involve text generation, such as language modeling, text completion, and machine translation (in autoregressive mode). Some examples are the GPT family
- Masked Self-Attention Mechanism: Prevents information flow from future tokens, ensuring autoregressive generation.
- Unidirectional Context: Only considers past tokens for generating the next token.
- Tasks: Best suited for text generation tasks where the output sequence is produced one token at a time.
Architecture
- Input Layer: The input is tokenized and embedded into continuous vector representations.
- Decoder Layer: Consists of multiple layers of masked self-attention and feed-forward neural networks. The masked self-attention ensures that the prediction for a given token depends only on the tokens before it.
- Output Layer: Each output token is generated sequentially, based on the context of previously generated tokens.
3. Encoder-Decoder Architectures
Encoder-decoder architectures, also known as sequence-to-sequence (Seq2Seq) models, are designed to transform an input sequence into an output sequence. These architectures are used for tasks that involve transforming one sequence into another, such as machine translation, text summarization, and question answering. Some examples are the original transformer architecture and T5
- Cross-Attention Mechanism: Allows the decoder to attend to different parts of the input sequence through the encoder’s context.
- Flexible Context Utilization: Can handle varying lengths of input and output sequences.
- Tasks: Best suited for tasks where the output sequence is derived from the input sequence.
Architecture
- Encoder: Similar to the encoder in encoder-only architectures. It processes the input sequence and generates a context representation.
- Decoder: Similar to the decoder in decoder-only architectures. It generates the output sequence token by token, conditioned on the context representation from the encoder.
- Attention Mechanism: Often includes an additional attention mechanism between the encoder and decoder to allow the decoder to focus on relevant parts of the input sequence.
Comparison Summary
| Feature | Encoder-Only | Decoder-Only | Encoder-Decoder |
|---|---|---|---|
| Context Direction | Bidirectional | Unidirectional (past to future) | Bidirectional (Encoder) + Unidirectional (Decoder) |
| Self-Attention | Yes | Masked | Yes (Encoder) + Masked (Decoder) + Cross-Attention |
| Primary Use Cases | Classification, NER, QA | Text Generation, Language Modeling | Machine Translation, Summarization, Seq2Seq Tasks |
| Representative Models | BERT, RoBERTa | GPT-2, GPT-3 | Transformer, T5, BART |