Deepseek, an overview and quick notes
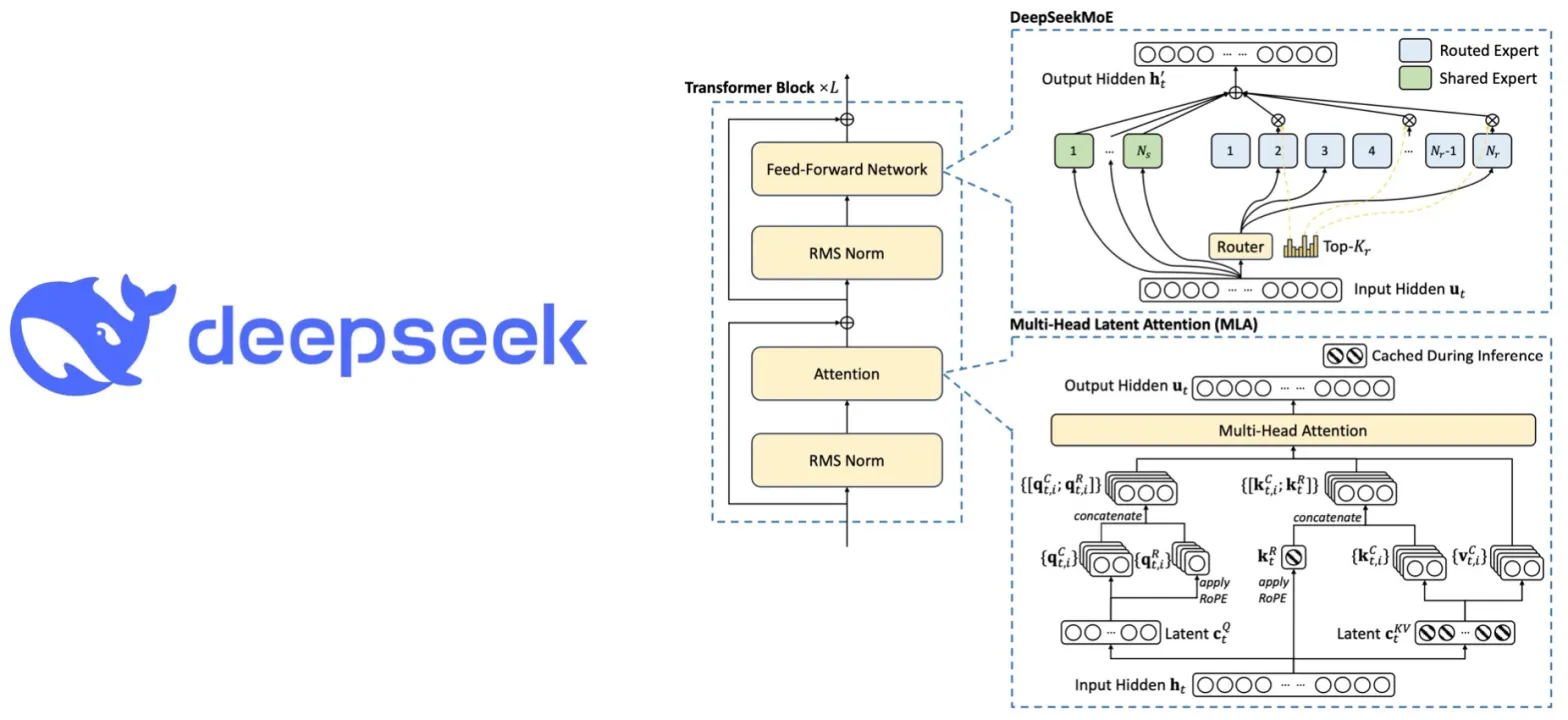
Some notes of DeepSeek-V3
- DeepSeek-V3 is a Mixture-of-Experts (MoE) language model with 671B total parameters, of which 37B are activated for each token
- Uses Multi-head Latent Attention (MLA) for efficient inference and DeepSeekMoE for cost-effective training
- Introduces an auxiliary-loss-free strategy for load balancing to minimize performance degradation while maintaining balanced expert utilization
- Implements a multi-token prediction training objective to enhance model performance
- Trained on 14.8T diverse tokens
- Uses FP8 mixed precision training with fine-grained quantization strategy
- Employs DualPipe algorithm for efficient pipeline parallelism with minimal communication overhead
- Achieves cost-effective training, requiring only 2.788M H800 GPU hours total: - 2664K hours for pre-training - 119K hours for context extension - 5K hours for post-training - Total cost approximately $5.576M at $2/GPU hour
- Outperforms other open-source models across multiple benchmarks
- Particularly strong in: - Math tasks (90.2% on MATH-500) - Code tasks (51.6% on Codeforces percentile) - Knowledge tasks (75.9% on MMLU-Pro)
- Demonstrates competitive performance against closed-source models like GPT-4 and Claude-3.5-Sonnet
- Supports context lengths up to 128K tokens through two-stage extension training
- Auxiliary-loss-free load balancing strategy that improves expert utilization without compromising performance
- Multi-token prediction training objective that enhances model capabilities while enabling speculative decoding
- FP8 training framework with tile-wise and block-wise quantization strategies
- DualPipe algorithm that achieves efficient pipeline parallelism with minimal communication overhead