GRPO on DeepSeek-r1
Proximal Policy Optimization (PPO)
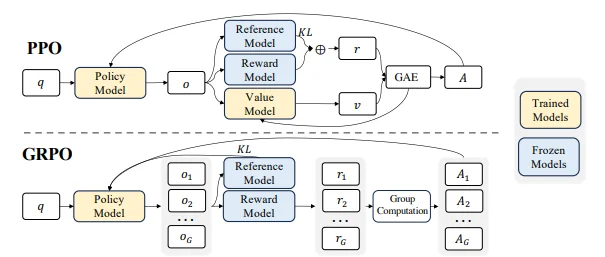
PPO is a reinforcement learning algorithm originally designed to update policies in a stable and reliable way. In the context of LLM fine-tuning, the model (the “policy”) is trained using feedback from a reward model that represents human preferences. Value Function (Critic): Estimates the “goodness” of a state, used with Generalized Advantage Estimation (GAE) to balance bias and variance. Basically it works as follows:
- Generate Rollouts: The LLM produces a set of text responses (rollouts) for a given prompt.
- Score with the Reward Model: Each response is scored.
- Compute Advantages: Using GAE, the algorithm computes how much better (or worse) each action (e.g., token choice) was compared to a baseline.
- Update the Policy: A PPO objective is used with a clipped surrogate loss to ensure updates are not too drastic. Additional terms (like a KL penalty and entropy bonus) help maintain stability and encourage exploration.
def ppo_loss_with_gae_entropy(old_policy_logprobs, new_policy_logprobs, advantages,
kl_penalty_coef, clip_epsilon, entropy_bonus_coef):
# Compute probability ratio between new and old policy actions
ratio = np.exp(new_policy_logprobs - old_policy_logprobs)
# Clipped surrogate objective prevents large policy updates
surrogate_objective = np.minimum(ratio * advantages,
np.clip(ratio, 1 - clip_epsilon, 1 + clip_epsilon) * advantages)
policy_loss = -np.mean(surrogate_objective)
# KL divergence penalty to keep new policy close to the old one
kl_divergence = np.mean(new_policy_logprobs - old_policy_logprobs)
kl_penalty = kl_penalty_coef * kl_divergence
# Entropy bonus encourages exploration (i.e., less certainty)
entropy = -np.mean(new_policy_logprobs)
entropy_bonus = entropy_bonus_coef * entropy
total_loss = policy_loss + kl_penalty - entropy_bonus
return total_lossDirect Preference Optimization (DPO)
DPO simplifies the training loop by skipping the reinforcement learning (RL) loop entirely. Rather than estimating rewards and advantages, DPO directly uses human preference data (pairs of preferred vs. dispreferred responses) to adjust the model. It compares the raw model outputs (logits) between a current model and a reference model (often an earlier, supervised-fine-tuned version) using a loss function similar to binary cross-entropy. So basically it works as follows:
- Collect Preference Data: Gather pairs of responses where human judges indicate which response they prefer.
- Evaluate with Two Models: Compute the logits for both the preferred and dispreferred responses using the current model and a reference model.
- Compute Log Ratios: Determine the relative “strength” (log probabilities) of preferred versus dispreferred responses.
- Optimize Directly: Use a loss function that, in effect, makes the current model more likely to generate preferred responses and less likely to generate dispreferred ones—all while staying close to the reference model.
def dpo_loss(policy_logits_preferred, policy_logits_dispreferred,
ref_logits_preferred, ref_logits_dispreferred, beta_kl):
# Convert logits to log probabilities (details abstracted)
policy_logprob_preferred = F.log_softmax(policy_logits_preferred, dim=-1).gather(...)
policy_logprob_dispreferred = F.log_softmax(policy_logits_dispreferred, dim=-1).gather(...)
ref_policy_logprob_preferred = F.log_softmax(ref_logits_preferred, dim=-1).gather(...)
ref_policy_logprob_dispreferred = F.log_softmax(ref_logits_dispreferred, dim=-1).gather(...)
# Calculate the log ratio comparing current model differences to reference differences
log_ratio = (policy_logprob_preferred - policy_logprob_dispreferred -
(ref_policy_logprob_preferred - ref_policy_logprob_dispreferred))
# Convert log ratio into a probability using a logistic function (Bradley-Terry model)
preference_prob = 1 / (1 + np.exp(-beta_kl * log_ratio))
# Compute loss as binary cross-entropy (minimizing negative log probability of preferred response)
loss = -np.log(preference_prob + 1e-8)
return lossGroup Relative Policy Optimization (GRPO)
GRPO is a twist on PPO that is designed to be leaner and faster—especially for complex reasoning tasks. Instead of relying on a separate value function (critic) to estimate advantages, GRPO uses a group-based approach: For a given prompt, a group of responses is generated. These responses are scored using the reward model. So basically it works as follows: 1. Generate a Group of Responses: For each prompt, sample several responses. 2. Score the Responses: Use a reward model to assign a reward to each response. 3. Compute Group Relative Advantages: Calculate advantages by comparing each response’s reward to the group mean (and optionally normalizing by the standard deviation). 4. Update the Policy: Use a PPO-like objective function that takes these group relative advantages into account.
def grae_advantages(rewards):
"""
Compute Group Relative Advantages by normalizing rewards within a group.
"""
mean_reward = np.mean(rewards)
std_reward = np.std(rewards)
normalized_rewards = (rewards - mean_reward) / (std_reward + 1e-8)
advantages = normalized_rewards # Here, advantage = normalized reward
return advantagesdef grpo_loss(old_policy_logprobs_group, new_policy_logprobs_group,
group_advantages, kl_penalty_coef, clip_epsilon):
"""
Compute the GRPO loss over a group of responses.
"""
group_loss = 0
# Loop over each response in the group
for i in range(len(group_advantages)):
advantage = group_advantages[i]
new_policy_logprob = new_policy_logprobs_group[i]
old_policy_logprob = old_policy_logprobs_group[i]
# Compute the probability ratio for the policy update
ratio = np.exp(new_policy_logprob - old_policy_logprob)
clipped_ratio = np.clip(ratio, 1 - clip_epsilon, 1 + clip_epsilon)
# Surrogate objective with clipping, similar to PPO
surrogate_objective = np.minimum(ratio * advantage, clipped_ratio * advantage)
policy_loss = -surrogate_objective
# KL divergence penalty to restrict too-large updates
kl_divergence = new_policy_logprob - old_policy_logprob
kl_penalty = kl_penalty_coef * kl_divergence
group_loss += (policy_loss + kl_penalty)
# Average the loss over the group of responses
return group_loss / len(group_advantages)