Classifier free diffusion guidance
One of the key techniques in diffusion models that has significantly improved their performance is classifier-free guidance. In this post, we’ll explore what classifier-free guidance is, how it works, and implement it from scratch in PyTorch.
What is Classifier-Free Guidance?
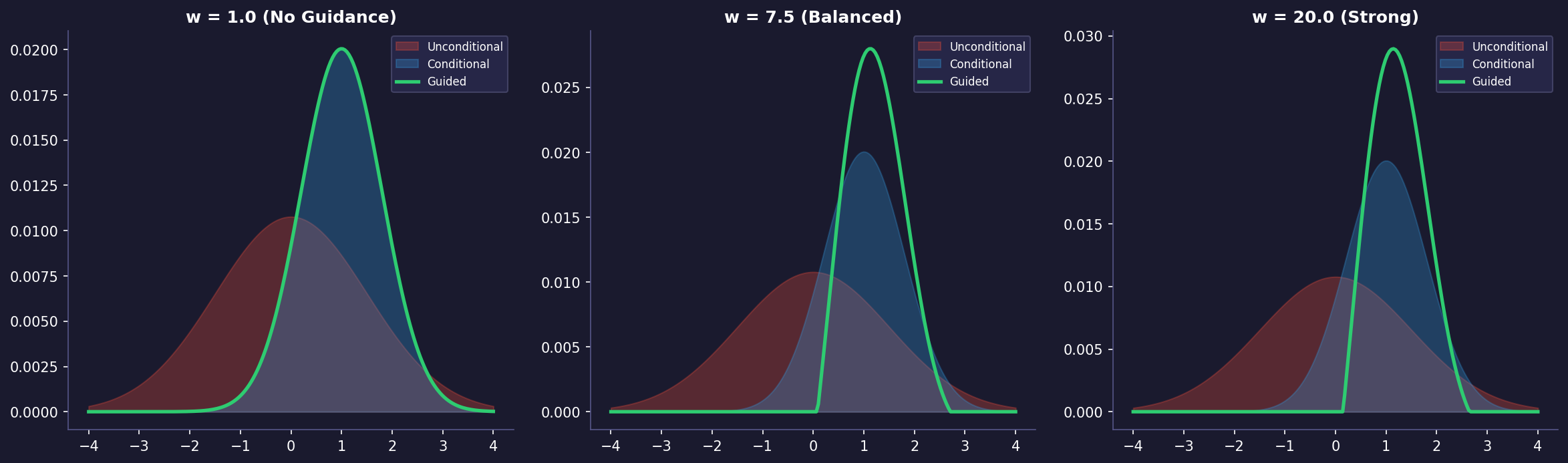
At its core, classifier-free guidance is an elegant technique that allows us to control the generation process of diffusion models without requiring a separate classifier. The key insight is that we can create a more powerful conditional generation process by combining both conditional and unconditional generation in a clever way.
Think of it like having two artists working together:
- One artist (conditional model) who follows specific instructions
- One artist (unconditional model) who creates freely without constraints
By combining their perspectives with different weights, we can create results that are both high-quality and well-aligned with our desired conditions.
The Mathematics Behind Classifier-Free Guidance
The core equation for classifier-free guidance is surprisingly simple:
ε̃ = (1 + w) * εθ(zt, c) - w * εθ(zt, ∅)Where: - ε̃ is the guided noise prediction - w is the guidance weight - εθ(zt, c) is the conditional model prediction - εθ(zt, ∅) is the unconditional model prediction
The beauty of this approach is that it doesn’t require training two separate models. Instead, we train a single model that can handle both conditional and unconditional generation.
Implementation: A Complete Example
Let’s implement classifier-free guidance for a diffusion model from scratch. We’ll build a system that can generate MNIST-like digits conditioned on class labels.
First, let’s create our improved diffusion model:
import torch
import torch.nn as nn
class DiffusionModel(nn.Module):
def __init__(self, input_dim=784, hidden_dim=256, num_classes=10):
super().__init__()
self.input_dim = input_dim
self.num_classes = num_classes
# Improved embedding with position encoding
self.class_embedding = nn.Sequential(
nn.Embedding(num_classes + 1, hidden_dim), # +1 for unconditional
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU()
)
# Time embedding
self.time_embed = nn.Sequential(
nn.Linear(1, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim)
)
# Enhanced U-Net architecture
self.encoder = nn.Sequential(
nn.Linear(input_dim + hidden_dim * 2, hidden_dim * 2),
nn.LayerNorm(hidden_dim * 2),
nn.ReLU(),
nn.Linear(hidden_dim * 2, hidden_dim),
nn.LayerNorm(hidden_dim),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim * 2),
nn.LayerNorm(hidden_dim * 2),
nn.ReLU(),
nn.Linear(hidden_dim * 2, input_dim),
nn.Tanh() # Bounded output
)
def forward(self, x, t, c=None):
batch_size = x.shape[0]
# Handle conditional vs unconditional
if c is None:
c = torch.full((batch_size,), self.num_classes, device=x.device)
# Get embeddings
c_emb = self.class_embedding(c)
t_emb = self.time_embed(t.unsqueeze(-1))
# Combine all information
x_c = torch.cat([x, c_emb, t_emb], dim=-1)
# Forward pass
h = self.encoder(x_c)
output = self.decoder(h)
return outputNow, let’s implement an improved training loop with classifier-free guidance:
def train_diffusion_model(model, dataloader, num_epochs=100, puncond=0.1, device='cuda'):
"""
Enhanced training loop with classifier-free guidance support
"""
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4, weight_decay=0.01)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, num_epochs)
for epoch in range(num_epochs):
model.train()
total_loss = 0
for batch, (x, c) in enumerate(dataloader):
batch_size = x.shape[0]
x = x.to(device)
c = c.to(device)
# Sample timesteps
t = torch.rand(batch_size, device=device)
# Create noise
epsilon = torch.randn_like(x)
z_t = alpha(t).view(-1, 1) * x + sigma(t).view(-1, 1) * epsilon
# Sometimes drop conditioning for unconditional training
mask = torch.rand(batch_size, device=device) < puncond
c_in = torch.where(mask, torch.full_like(c, model.num_classes), c)
# Get model prediction
epsilon_theta = model(z_t, t, c_in)
# Compute loss with improved weighting
loss = torch.nn.functional.mse_loss(epsilon_theta, epsilon, reduction='none')
loss = loss * (1 + t.view(-1, 1)) # Weight loss by timestep
loss = loss.mean()
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
total_loss += loss.item()
scheduler.step()
avg_loss = total_loss / len(dataloader)
print(f"Epoch {epoch}: Average Loss = {avg_loss:.4f}")
return modelFinally, let’s improve the sampling process with classifier-free guidance:
def sample_with_guidance(model, c, w, steps=50, data_shape=[1, 28, 28], device='cuda'):
"""
Enhanced sampling with classifier-free guidance
"""
model.eval()
batch_size = 1
# Create log-SNR sequence with improved spacing
lambda_sequence = torch.linspace(0, 1, steps)
lambda_sequence = torch.sigmoid(10 * (lambda_sequence - 0.5)) # Better spacing
# Initialize with noise
z_t = torch.randn(batch_size, *data_shape, device=device)
# Prepare conditioning
c = torch.tensor([c], device=device)
with torch.no_grad():
for i in range(len(lambda_sequence) - 1):
lambda_t = lambda_sequence[i]
lambda_next = lambda_sequence[i + 1]
# Get conditional and unconditional score estimates
epsilon_theta_c = model(z_t, lambda_t, c)
epsilon_theta = model(z_t, lambda_t, None)
# Apply classifier-free guidance
epsilon_guided = (1 + w) * epsilon_theta_c - w * epsilon_theta
# Improved DDIM-like step
x_pred = (z_t - sigma(lambda_t).view(-1, 1, 1) * epsilon_guided) / alpha(lambda_t).view(-1, 1, 1)
z_t = alpha(lambda_next).view(-1, 1, 1) * x_pred + sigma(lambda_next).view(-1, 1, 1) * epsilon_guided
return z_t[0]Understanding the Improvements
Our implementation includes several key improvements over the basic version:
-
Enhanced Architecture: - Added time embeddings for better temporal understanding - Included layer normalization for stable training - Added residual connections in the U-Net structure
-
Improved Training: - Using AdamW optimizer with weight decay for better regularization - Implemented learning rate scheduling - Added gradient clipping to prevent exploding gradients - Weighted loss by timestep to focus more on later denoising steps
-
Better Sampling: - Improved timestep spacing using sigmoid scaling - More stable DDIM-like stepping procedure - Better handling of batch dimensions