Temporal Graph Networks: A Deep Dive into Dynamic Graph Learning
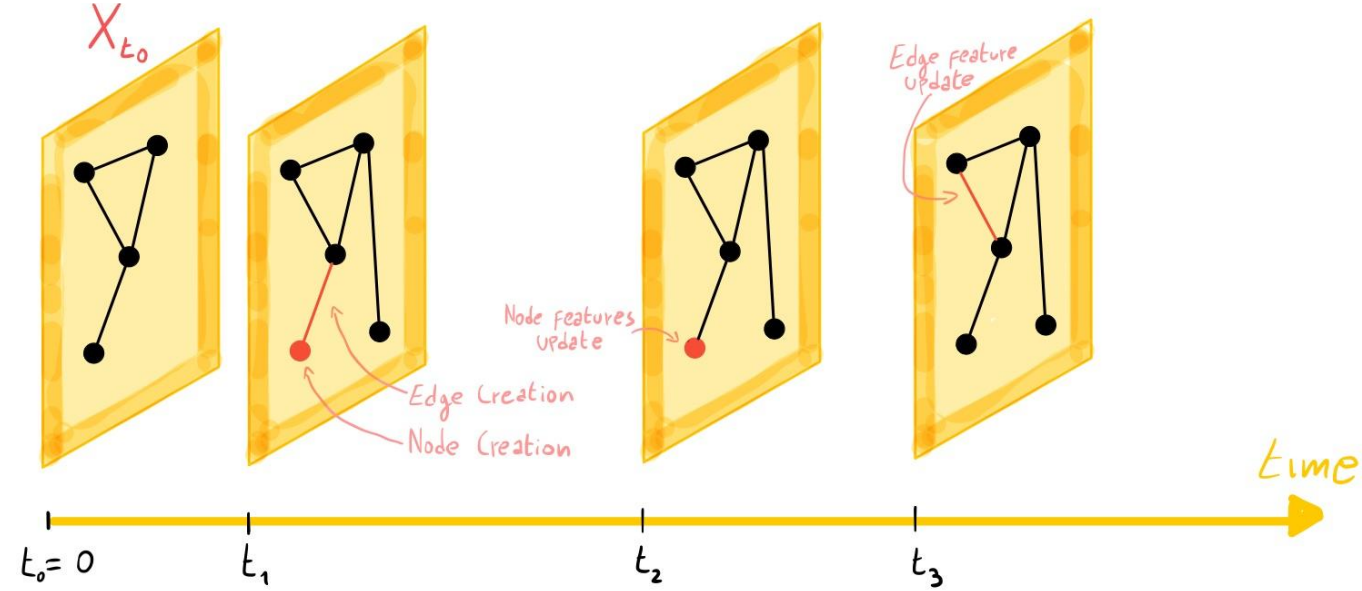
Real-world networks are rarely static. Social networks evolve as users form new connections, financial networks change with each transaction, and biological networks transform as proteins interact. Traditional Graph Neural Networks (GNNs) weren’t designed for this dynamism. Enter Temporal Graph Networks (TGNs), a powerful framework for learning on dynamic graphs.
Understanding Dynamic Graphs
Before diving into TGNs, let’s clarify what we mean by dynamic graphs. A temporal graph can be represented as a sequence of time-stamped events: G = {x(t₁), x(t₂), …}. Each event can be:
- Node-wise: Adding/updating a node with features
- Edge-wise: Creating an interaction between nodes
Core Components of TGN
Memory Module
The memory module is TGN’s secret weapon. Each node maintains a memory state that captures its history of interactions. This memory gets updated with each new event, allowing the network to learn long-term dependencies.
Message Function
When an interaction occurs between nodes, messages are computed to update their memories. Here’s how the message functions work:
class TemporalGraphNetwork:
def __init__(self, node_features, edge_features, memory_dimension):
self.node_features = node_features
self.edge_features = edge_features
self.memory = {node_id: np.zeros(memory_dimension) for node_id in node_features}
def compute_messages(self, source, target, time, edge_features):
"""Compute messages for source and target nodes."""
# Get current memory states
source_memory = self.memory[source]
target_memory = self.memory[target]
# Compute time delta from last update
delta_time = time - self.last_update[source]
# Compute messages for both nodes
source_message = self.message_function(
source_memory=source_memory,
target_memory=target_memory,
delta_time=delta_time,
edge_features=edge_features
)
target_message = self.message_function(
source_memory=target_memory,
target_memory=source_memory,
delta_time=delta_time,
edge_features=edge_features
)
return source_message, target_message
def message_function(self, source_memory, target_memory, delta_time, edge_features):
"""Simple concatenation-based message function."""
return np.concatenate([
source_memory,
target_memory,
[delta_time],
edge_features
])Message Aggregator
When multiple events involve the same node in a batch, their messages need to be aggregated:
def aggregate_messages(self, messages, aggregation_type="last"):
"""Aggregate multiple messages for the same node."""
if aggregation_type == "last":
return messages[-1] # Return most recent message
elif aggregation_type == "mean":
return np.mean(messages, axis=0) # Average all messagesMemory Updater
The memory updater is typically implemented using a GRU or LSTM to update node memories based on aggregated messages:
def update_memory(self, node_id, message, time):
"""Update node memory using GRU-like update."""
current_memory = self.memory[node_id]
# GRU-like update equations
update_gate = sigmoid(
self.W_update @ np.concatenate([current_memory, message])
)
reset_gate = sigmoid(
self.W_reset @ np.concatenate([current_memory, message])
)
candidate_memory = tanh(
self.W_candidate @ np.concatenate([
reset_gate * current_memory,
message
])
)
# Update memory
self.memory[node_id] = (
update_gate * current_memory +
(1 - update_gate) * candidate_memory
)
self.last_update[node_id] = timeEmbedding Module
The embedding module generates node embeddings using the current memory state and graph structure:
def compute_embedding(self, node_id, time, num_layers=1):
"""Compute node embedding using temporal graph attention."""
current_embedding = self.memory[node_id]
for layer in range(num_layers):
# Get temporal neighbors
neighbors = self.get_temporal_neighbors(node_id, time)
# Compute attention scores
attention_scores = self.compute_temporal_attention(
query=current_embedding,
keys=[self.memory[n] for n in neighbors],
times=[self.last_update[n] for n in neighbors]
)
# Aggregate neighbor information
neighbor_info = sum(
score * self.memory[neighbor]
for score, neighbor in zip(attention_scores, neighbors)
)
# Update embedding
current_embedding = self.embedding_update(
current_embedding,
neighbor_info
)
return current_embeddingTraining Process
Training TGN requires careful handling of temporal dependencies. Here’s the main training loop:
def train(self, temporal_edges, batch_size=200):
"""Train the model on temporal edges."""
message_store = {} # Store for raw messages
for batch in create_batches(temporal_edges, batch_size):
# 1. Update memories using stored messages
self.process_message_store(message_store)
# 2. Compute embeddings
source_embeddings = [
self.compute_embedding(edge.source, edge.time)
for edge in batch
]
target_embeddings = [
self.compute_embedding(edge.target, edge.time)
for edge in batch
]
# 3. Compute loss
loss = self.compute_loss(
source_embeddings,
target_embeddings,
batch.labels
)
# 4. Backward pass
loss.backward()
# 5. Store raw messages for next batch
for edge in batch:
message_store[edge.source] = (
edge.source,
edge.target,
edge.time,
edge.features
)
message_store[edge.target] = (
edge.target,
edge.source,
edge.time,
edge.features
)Key Advantages and applications
- Memory Efficiency: TGN maintains a compact memory state for each node instead of storing the entire history.
- Temporal Awareness: The framework naturally handles time-stamped events and evolving graphs.
- Flexibility: Different message, aggregation, and memory update functions can be used based on the specific application.
- Scalability: The batched training process allows for efficient processing of large temporal graphs.
TGNs have shown remarkable success in various domains: - Dynamic link prediction in social networks - User-item interaction modeling in recommender systems - Temporal knowledge graph completion - Financial fraud detection - Traffic prediction
Implementation Considerations
- Batch Size: Smaller batches ensure more frequent memory updates but slower training.
- Memory Dimension: Larger memory can capture more complex patterns but requires more computation.
- Neighbor Sampling: Sampling recent neighbors often works better than uniform sampling.
- Time Encoding: Different time encoding strategies can be used based on the temporal patterns in the data.