Diffusion models or Autoencoders?
Unmasking the Secret Link: Are Diffusion Models Just Fancy Autoencoders?
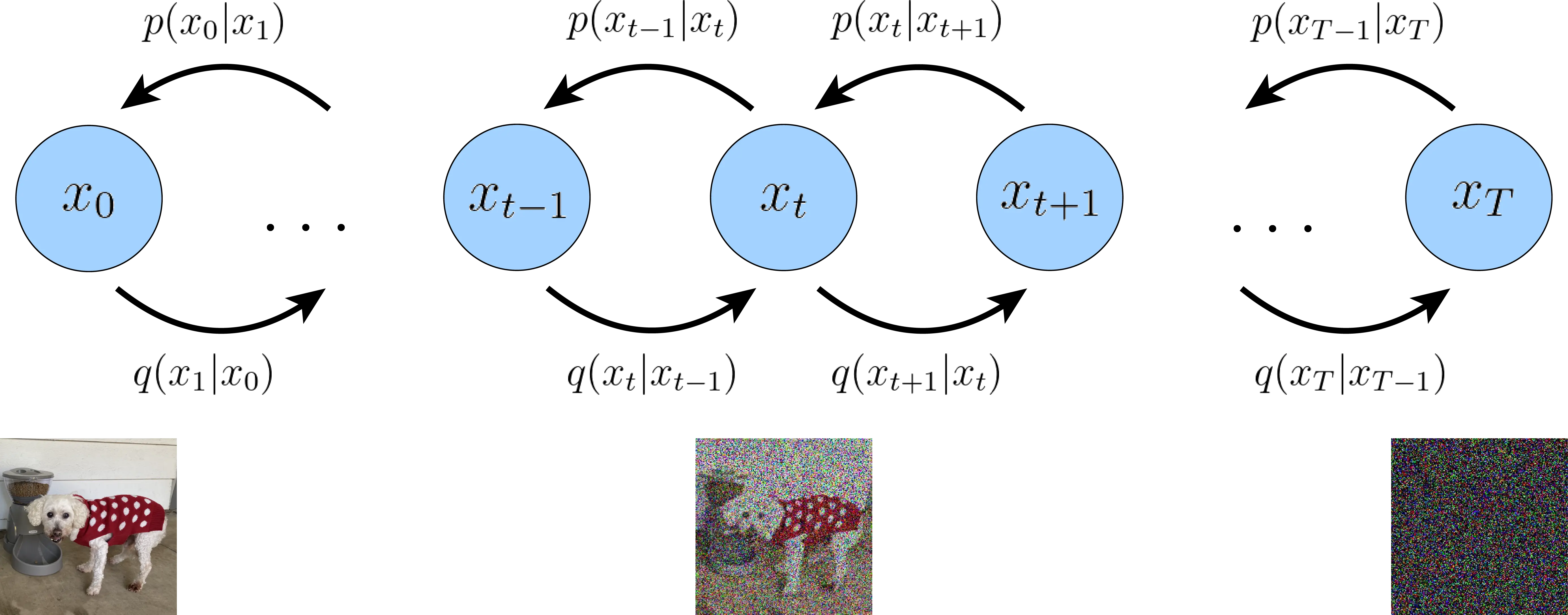
Recent advancements in generative AI have brought diffusion models to the forefront, particularly for their impressive performance in image generation. While these models are often seen as distinct from traditional approaches, there’s a compelling argument for viewing diffusion models as a form of hierarchical autoencoder.
The key insight lies in the similarity between the noise addition process in diffusion models and the compression step in autoencoders. When a diffusion model adds noise to data, it’s effectively compressing the information, retaining only the most robust features. This is analogous to how an autoencoder’s encoder compresses input data into a lower-dimensional representation.
Conversely, the denoising process in diffusion models resembles the reconstruction phase of autoencoders. The critical difference is that diffusion models perform this reconstruction gradually, over multiple steps, allowing them to capture a hierarchy of details. This multi-step process creates a series of latent representations at different levels of abstraction, much like a hierarchical autoencoder.
The noise in diffusion models serves a similar purpose to the bottleneck layer in autoencoders, acting as an information constraint that forces the model to learn efficient, robust representations. This perspective suggests that diffusion models implicitly learn a series of nested representations, each corresponding to a different noise level.
Viewing diffusion models through this lens opens up new possibilities for research and improvement. It suggests potential hybrid architectures combining elements of both approaches, and hints at applications beyond generation, such as in data compression.