Simple Reinforcement Learning Example
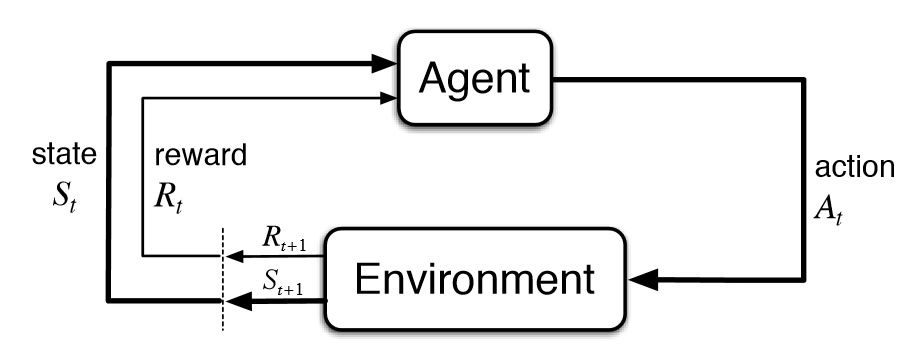
A simple RL example, where i want an agent to navigate a grid to reach a goal while avoiding holes. For more details here is the colab where I implemented the RL example Link to code
import gym
import numpy as np
env = gym.make('FrozenLake-v1', is_slippery=False, render_mode='human')
num_episodes = 1000
max_steps_per_episode = 100
learning_rate = 0.1
discount_rate = 0.99
exploration_rate = 1.0
max_exploration_rate = 1.0
min_exploration_rate = 0.01
exploration_decay_rate = 0.001
q_table = np.zeros((env.observation_space.n, env.action_space.n)) # q table
for episode in range(num_episodes):
state = env.reset()
done = False
step = 0
for step in range(max_steps_per_episode):
#
# Exploration-exploitation trade-off
#
exploration_threshold = np.random.uniform(0, 1)
if exploration_threshold > exploration_rate:
action = np.argmax(q_table[state, :])
else:
action = env.action_space.sample()
#
# Take the action and observe the outcome
#
new_state, reward, done, info = env.step(action)
#
# Update Q-table
#
q_table[state, action] = q_table[state, action] + learning_rate * (reward + discount_rate * np.max(q_table[new_state, :]) - q_table[state, action])
#
# Transition to the new state
#
state = new_state
#
# If the episode is done, break the loop
#
if done:
break
#
# Decay the exploration rate
#
exploration_rate = min_exploration_rate + (max_exploration_rate - min_exploration_rate) * np.exp(-exploration_decay_rate * episode)
state = env.reset()
env.render()
done = False
while not done:
action = np.argmax(q_table[state, :])
new_state, reward, done, info = env.step(action)
state = new_state
env.render()
print("Test completed.")